FAQ-1032 密度散布図の検証
density-dots-validation
最終更新日:2019/12/16
密度ドットプロットは、データ密度を示す散布図で、ポイントはデータ密度でカラーマップされます。密度はカーネル密度推定を使用して計算されます。
カーネル密度推定を計算するために、Originは2Dビン近似と2D補間を利用する高速アルゴリズムを使用します。最初の2Dビン化が(x、y)ポイントで実行され、ビンカウントの行列を取得します。次に、2D高速フーリエ変換を使用して、各グリッドの密度値を計算するための離散畳み込みを実行します。密度値の4乗根は、密度スケールをカラースケールにマッピングするために計算されます。
Originは同じデータセットからRと同様の結果を生成できます。
RとOriginの結果の比較
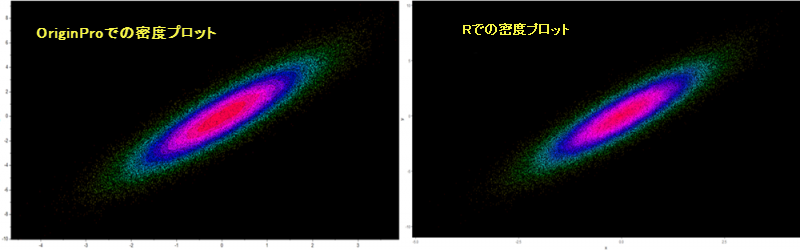
リファレンス
データ:
1つの応答変数(y), 1つの予測変数(x)
観測数100000
生成されたデータ
データファイル: DP.csv
Originプロジェクトファイル: density_dots_validation_sample.opju
このグラフを作成するRコード
xx= read.csv("DP.csv",header=FALSE)
as.list(body(smoothScatter))
trace("smoothScatter",quote(browser()),at=19)
w<-c(0.056990976577602, 0.13442535086237)
smoothScatter(xx, nrpoints = 0,nbin=151,bandwidth=w)
#Debug and run following script
#Type "n" to enter line 19
stopifnot((nx <- length(xm)) == nrow(dens),
(ny <- length(ym)) == ncol(dens))
ixm <- 1L + as.integer((nx-1)*(x[,1]-xm[1])/(xm[nx]-xm[1]))
iym <- 1L + as.integer((ny-1)*(x[,2]-ym[1])/(ym[ny]-ym[1]))
z<-dens[cbind(ixm, iym)]
df<-data.frame(x=x[,1],y=x[,2],z=z)
library(ggplot2)
sp<-ggplot(df, aes(x,y,colour=z)) + geom_point(shape=".")+
theme(panel.background = element_rect(fill = 'black'),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_blank())
sp
cval<-seq(0,1,length.out=6)
sp+scale_color_gradientn(values = cval,colours = rainbow(20))
キーワード:検証, Rとの比較
|