LabTalkがサポートする関数LT-Supported-Functions
文字列関数
| Note: すべての関数は、 Origin 8 SR6 以降のバージョンでのみ利用できます。
|
| 名前
|
説明
|
| Between(str$, str1$, str2$)$
|
str$のstr1$とstr2$の間の文字列または文字を抽出します。 サンプル:
-
Between([Results]"March 2009"!"Average Return"[1:31],"!","[")$ は "Average Return"を返します。
|
| Char(number)$
|
1-255の整数をとり、ASCII文字を返します。 サンプル:
-
char(65)$ は Aを返します。
-
char(col(B))$ はcol(B)の整数値に対応するASCII文字を返します。
|
| Code(str$)
|
文字列をとり、最初の文字のASCII文字を返します。例:
-
str$ = "abc"; code(str$) は 97を返します。
-
code(col(D)) はcol(D)の文字列の最初の文字のASCIIコードに対応する整数を返します。
|
| Compare(str1$, str2$ [,Case])
|
2つの文字列をとり、一致した場合1、不一致の場合0を返します。 オプションCaseは、大文字と小文字の区別を制御し、1=真(デフォルト)、0=偽 です。 サンプル:
-
str1$ = "ABC"; str2$ = "abc"; compare(str1$,str2$,0) は 1を返します。
-
compare(col(F), col(G),1)は、文字列または大文字と小文字が一致しない場合は"0"を返し、文字列と大文字と小文字が一致した場合は"1"を返します。
|
| CompareNoCase(str$, str2$)
|
2つの文字列を取り、0 (同一)、-1(アルファベット順でstr$がstr2$より小さい)、または1(str$がstr2$より大きい)を返します。 サンプル:
-
str1$ = "ABC"; str2$ = "abc"; comparenocase(str1$,str2$) は 0を返します。
-
comparenocase("ijk","ab") は 1を返します。
-
comparenocase("ijk","xyz") は -1を返します。
|
| EnvVar(variableName$)
|
文字列を取り、対応するWindows環境変数に格納されている文字列値を返します。この文字列が有効なWindows環境変数文字列でない場合、欠損値が返されます。 サンプル:
-
EnvVar("appdata")$はアプリケーションデータフォルダへのディレクトリパスを返します。
|
| Exact(str1$, str2$)
|
2つの文字列をとり、大文字と小文字の区別を含めて一致した場合1、不一致の場合0を返します。例:
-
str1$ = "ABC"; str2$ = "abc"; exact(str1$,str2$) は 0を返します。
-
exact(col(F), col(G)) は完全に一致する文字列でない場合は"0"を返し、完全に一致する場合は"1"を返します(大文字と小文字を含む)。
|
| Find(within$,find$[,StartPos])
|
within$ でfind$を検索し、見つかった場合within$内の最初の文字の位置を返し、見つからなかった場合-1を返します。 オプションStartPosは、検索開始位置を制御します。(デフォルト=1)大文字小文字の区別あり。ワイルドカードは使用できません。 例:
-
str1$ = "abcde"; str2$ = "bc"; find(str1$,str2$) は 2を返します。
-
find(col(G),col(J)) は、最初の文字から始まるcol(G)文字列をcol(J)文字列で検索します。見つかった場合は、col(G)文字列内のcol(J)文字列の位置を返します。
|
| FindOneOf(within$,find$)
|
within$内で見つかった最初の文字をfind $で検索し、見つかった場合は、最初に見つかった文字の1ベースインデックスを返します。大文字小文字の区別あり。ワイルドカードは使用できません。 例:
-
str1$ = "abcde"; str2$ = "xb"; findOneOf(str1$,str2$) は 2を返します。
|
| GetAt(str$,index)
|
str$のindexで指定された単一の文字を返します。例:
-
str$ = "sss abc"; GetAt(str1$,5) は 97を返します。
|
| GetFileExt(strFile$)$
|
フルパスstrFile$からファイル拡張子を取得します。例:
-
GetFileExt("origin.ini")$ は "ini"を返します。
|
| GetFileName(strFile$,bRemoveExt)$
|
フルパスstrFile $からファイル名(bRemoveExt = 1の場合は拡張子なし)を取得します。例:
-
GetFileName("%Yorigin.ini")$ は "origin.ini"を返します。
|
| GetFilePath(strFile$)$
|
フルパスstrFile$からファイル拡張子を取得します。例:
-
GetFilePath("%Yorigin.ini")$ はパス文字列を返します。
|
| GetLength(str$)
|
str$の長さを取得します。例:
-
GetLength("origin.ini")$は10を返します。
|
| GetToken(str$,n,chDelimiter)$
|
トークンがchDelimiterで区切られているn番目のトークンを返します。例:
-
GetToken("sss|abc|def|xyz", 3,"|")$ は "def"を返します。
|
| IsEmpty(str$)
|
MS ExcelのISBLANK関数と同様です。ワークシートのセルが空かどうかを判断するために使用します。引数 str には、セルアドレスまたは値の列を指定できます。 例:
-
isempty(col(A)[2]$)=; // return 0 if cell row 2, col 1 contains a value; or 1 if empty.
|
| IsFile(str$)
|
strが有効なフルパスファイル名の例であるかどうかをテストします。例:
-
IsFile("origin.ini")=; // return 1 if the file exist.
|
| IsFormula(str$)
|
ワークシートのセルにセル数式が含まれているかどうかを確認します。 サンプル:
-
isformula(A2)=; // return 1 if cell row 2, col 1 contains cell formula; otherwise return 0.
|
| IsPath(str$)
|
strが有効なファイルパスの例であるかどうかをテストします。例:
|
| Left(str$, n)$
|
文字列str$をとり、左から数えてn文字までを返します。 サンプル:
-
str$ = "abcde"; Left(str$,3)$ は abcを返します。
-
left(col(G),3)$ はcol(G)文字列の左端の3文字を返します。
|
| Len(str$)
|
文字列str$をとり、文字数を返します。例:
-
str$ = "abc ABC"; Len(str$) は 7を返します。
-
len(col(G))はcol(G)文字列の文字数を返します。
|
| Lower(str$)$
|
文字列str$をとり、小文字に変換します。例:
-
str1$ = "ABCDE"; str2$ = Lower(str1$)$ は abcdeを返します。
-
lower(col(F))$ 小文字のcol(F)の文字列を返します。
|
| MakeCSV(str$[, quote, output_delim, input_delim$])$
|
区切り文字を持つ文字列をとり、CSVに変換します。 出力を囲むためにオプションquoteを使用し、0(デフォルト)=囲み文字なし、1=一重引用符、2=二重引用符 を指定します。オプションoutput_delimは、 0=コンマ、1=セミコロン です。オプションinput_delim$は、ソース文字列の区切り文字を指定します。スペース区切りの場合は必要ありません。例:
-
str$ = "This is a test value"; MakeCSV(str$, 1, 0)$ は 'This','is','a','test','value'を返します。
-
makecsv(col(N),0,0)$ col(N)内のスペース区切りの文字列を取得し、カンマ区切りの値の文字列を返します。
|
| Match(within$,find$[,Case])
(2015 SR0)
|
この関数は文字列find$とwithin$を比較し、内容が互いに一致するかを確認します。1(真、一致)または0(偽、不一致)を返します。文字列find$では"*" や "?" といったワイルドカードの使用をサポートしています。また、Caseで大文字と小文字の区別を制御します。0(デフォルト)=偽、1=真 です。例:
-
str1$ = "From: test@Originlab.com"; str2$ = "F*com"; Match(str1$,str2$); は 1を返します。
|
| MatchBegin(within$,find$[,StartPos,Case])
|
文字列within$を探し、find$の開始位置に応じた整数を返します。見つからない場合には-1を返します。 "*" や "?" といったワイルドカードの使用をサポートしています。オプションStartPosは、検索を始める文字の位置を指定します。デフォルトでは 1=最初の文字からの検索 です。オプションCaseは、大文字と小文字の区別を制御し、0=偽(デフォルト)、1=真 です。例:
-
str1$ = "From: test@Originlab.com"; str2$ = "From*@"; MatchBegin(str1$,str2$,1); は 1を返します。
-
matchbegin(col(a)," ") col(a)の最初の空白の開始位置を返します。見つからない場合は-1を返します。
|
| MatchEnd(within$, find$[, StartPos, Case])
|
文字列within$を探し、find$の終了位置に応じた整数を返します。見つからない場合には-1を返します。 "*" や "?" といったワイルドカードの使用をサポートしています。オプションStartPosは、検索を始める文字の位置を指定します。デフォルトでは 1=最初の文字からの検索 です。オプションCaseは、大文字と小文字の区別を制御し、0=偽(デフォルト)、1=真 です。例:
-
str1$ = "From: test@Originlab.com"; str2$ = "From*@"; MatchEnd(str1$,str2$,1); は 11を返します。
-
MatchEnd(col(A),col(B)) col(a)内のcol(b)文字列の終了位置を返します。一致しない場合は-1を返します。
|
| Mid(str$, StartPos [, n])$
|
文字列str$をとり、StartPosからのn文字を返す、またはnが指定されていない場合にはStartPosから全てを返します。 サンプル:
-
str$ = "aabcdef"; Mid(str$,2,3)$ は abcを返します。
-
str$ = "aabcdef"; Mid(str$,2)$ は abcdefを返します。
-
mid(col(a),1,3)$ col(a)内の文字列の最初の3文字を返します。
|
| NumberValue(str$ [, Decimal$, Group$])
|
文字列または文字列のベクトルを受け取り、数値として返します。オプション Decimal は、文字列の10進区切り文字を解釈するために使用されます。オプション Group はグループ区切り文字を解釈するために使用されます。文字列とオプションは引用符で囲みます。 サンプル:
-
numbervalue("1,000.05")=; // returns 1000.05 (US regional settings)
-
numbervalue("5.000,0", ",", ".")=; // returns 5000 (US regional settings)
|
| Replace(within$, StartPos, n, replace$)$
|
within$内のn文字をStartPosから始めて文字列replace$で置換します。 文字列replace$の長さはnと異なっていても問題ありません。例:
-
Replace(abcdefghijklmn,3,5,123456)$ は ab123456hijklmnを返します。
-
replace(col(a),1,4,"Replacement string ")$ col(a)の最初の4文字を文字列"Replacement string"(スペースを含む)に置き換えます。
|
| Right(str$, n)$
|
文字列str$をとり、右から数えてn文字までを返します。 サンプル:
-
str$ = "abcde"; Right(str$,n)$ は cdeを返します。
-
right(col(d),8) col(d)内の文字列の一番右にある8文字を返します。
|
| Search(within$, find$[, StartPos])
|
文字列within$で、文字列find$を探し、位置を返します。ない場合には -1 を返します。 大文字と小文字の区別なし。ワイルドカード無効。オプションStartPosは検索開始位置を制御します。(デフォルト=1)例:
-
within$ = "abcde"; find$ = "BC"; Search(within$,find$) は 2を返します。
-
search(col(c),"sample") col(c)内の文字列内の"sample"という単語の位置を返します。
|
| SpanExcluding(source$, strEx$)
|
strExから文字が最初に出現する前のすべての文字を抽出して返します。大文字と小文字を区別します。例:
-
str1$= "Hello World! Goodbye!"; str2$ = "ho"; SpanExcluding(str1$, str2$)$= ; Hellを返します。
|
| SpanIncluding(source$, strIn$)
|
strInで識別される文字のセットに含まれる最初の文字から始めて、文字列ソースから文字を抽出します。大文字と小文字を区別します。例:
-
str1$= "cabinet"; str2$ = "acB"; SpanIncluding(str1$, str2$)$= ; caを返します。
|
| Substitute(within$,sub$,find$ [, n])$
|
within$内のfind$を探し、sub$で置き換えます。 オプションでn番目に見つかったものだけを置き換えます。例:
-
Substitute(abcdefabcdef,12,bcd,0)$ は a12efa12efを返します。
-
substitute(col(c),"experiment: ","expt.",1) col(a)内の文字列を検索し、expt.の代わりにexperiment:を置換し、最初に見つかったインスタンスのみを置換します。
|
| Text(d[,fmt$])$
(9.1 SR0)
|
double型を文字列に変換します。 オプションfmt$では出力をフォーマットしこれらの値をとります。指定されていない場合、列フォーマットを使用します。@SD桁を使用するために、空の文字列""を使用します。Origin全体の設定を使用するため、「*」を使用します。例:
-
Text(2.01232,"*3")$ は 2.01を返します。
-
Text(Date(7/10/2014),D1)$ は Thursday, July 10, 2014を返します。
-
text(date(col(b)),D1)$ 日付データの列を取得し、"Wednesday, March 05, 2014"の形式の文字列を返します。
|
| Token(str$,iToken[, iDelimiter])$
|
文字列str$をとり、インデックスiTokenに応じた部分文字列を返します。 オプションiDelimiterは区切り文字のASCII値で、0(デフォルト)=あらゆる空白、32=単一スペース、124= "|" です。"_" (ASCII 95), "|"(ASCII 124) などのほとんどの区切り文字をiDelimiterとして直接使用できます。例:
-
str1$="This is my string"; Token(str1$,3)$ は myを返します。
-
token(col(c),2) col(c)の文字列の2番目のトークン(空白で区切られたもの)を返します。
-
token(col(b), 3, ":") col(b)の文字列の中でコロンで区切られた3番目のトークンを返します。
いくつかのシンボル文字は直接iDelimiterで使用できませんが、ASCII値はいつでも適用できます。
|
| Trim(str$[, n])$
|
文字列str$をとり、スペースを除きます。 パラメータnは、スペースをどのように取り除くかを制御し、0(デフォルト)=先行+後続、1=全て除く です。例:
-
str1$ = " abc ABC "; Trim(str1$,0)$は abc ABCを返します。
-
trim(col(a),0) 先頭と末尾のスペースを制御したcol(c)形式の文字列を返します。
|
| Upper(str$)$
|
文字列str$をとり、大文字で返します。 サンプル:
-
str1$ = "abcde"; Upper(str1$)$ は ABCDEを返します。
-
upper(col(c))$ col(c)の文字列を大文字で返します。
|
| Value(str$)
|
文字列数str$をとり、double型として返します。 サンプル:
-
str$ = "+.50"; Value(str$) は 0.5を返します。Note: atof() 関数を確認してください。
-
value(col(e)) col(e)で文字列番号を取得し、double型の数値として返します。
|
$表記と文字列関数に関する注意
Note:文字列を操作するときに "$"を使用すると、混乱することがあります。
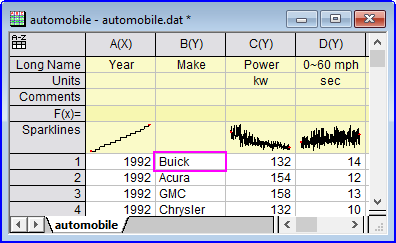
aa$=col(b)[1];
aa$=;
// returns
col(b)[1]
aa$=col(b)[1]$;
aa$=;
// returns
Buick
aa$=upper(col(b)[1]$);
aa$=;
// returns
upper(col(b)[1]$)
aa$=upper(col(b)[1]$)$;
aa$=;
// returns
BUICK
数学関数
| 名前
|
説明
|
| abs(x)
|
xの絶対値を返します。 サンプル:
-
abs(-2.5) は 2.5を返し、abs(0/0) は --(欠損値)を返します。
-
abs(col(b)) col(b)内のすべての要素の絶対値を返します。
|
| ceil(x[, sig])
(2019 SR0)
|
指定した値xを0から離れた位置に調整し、xに最も近いsigの倍数に調整して値を返します。 サンプル:
-
ceil(2.5, 2) は 4を返します。
-
ceil(-2.5, 2) は -2を返します。
|
| Combina(n,k)
(2019 SR0)
|
与えられた n 要素から、k 要素選んだときの組み合わせの数を返します。 サンプル:
|
| Combine(n1,n2)
|
与えられた n1 要素から、n2 要素を選んだ時の組み合わせの数を返します。 サンプル:
-
combine(4,2) は 6を返します。
-
combine(col(a),2 col(a)の値の2要素の組み合わせの数を返します。
|
| Distance(px1, py1, px2, py2)
|
2点のXY座標をとり、最短距離を返します。 サンプル:
-
distance(0,0,0,1) は 1を返します。
-
distance(col(g),col(h),col(i),col(j)) 1を返すこともできます。
|
| Distance3D(px1, py1, pz1, px2, py2, pz2)
|
2点のXYZ座標をとり、3Dでの最短距離を返します。 サンプル:
-
distance3d(0,0,1,0,0,2) は 1を返します。
-
distance3d(col(a),col(b),col(c),col(d),col(e),col(f)) 1を返すこともできます。
|
| exp(x)
|
eのx乗を返します。 Note: x > 667 のときには欠損値を返します。例:
-
exp(0) は 1を返します。
-
exp(col(a)) col(a)の値乗を返します。
|
| expm1(x)
|
xの小さい値に対してexp(x)-1の値を正確に返します。 例:
-
expm1(0.00574) は 0.0057565053651536を返します。
|
| fact(n)
|
非負の整数値の階乗を返します。 Note: n > 170 のときは欠損値を返します。Log_gamma関数を参照してください。例:
-
fact(3) は 6を返します。
-
fact(col(a)) はcol(a)の値の階乗を返します。。
|
| factdouble(n)
|
非負の整数値の二重階乗を返します。
n=奇数の場合、シーケンスは1*3*5...(n-2)*n、n=偶数の場合、シーケンスは2*4*6...(n-2)*n、n=0の場合、1として評価されます。n >299 の場合、欠損値を返します。例:
-
factdouble(6) は 48を返します。
-
factdouble(col(a)) col(a)の値の階乗を返します。
|
| floor(x[, sig])
(2019 SR0)
|
与えられた値xを0に近づけ、xに最も近い有意数の倍数に調整して値を返します。 サンプル:
-
floor(2.5, 2) = ; は 2を返します。
-
floor(-2.5, -2) = ; は -2を返します。
|
| gcd(n1, n2[, ...])
(2019 SR0)
|
与えられた整数n1, n2, n3などのグループの最大公約数を返します。 例:
|
| frac(x)
|
double型の小数部分を返します。
サンプル:
-
frac(3.1415) = ; は 0.1415を返します。
|
| HaversineDistance(lon1,lat1,lon2,lat2,r[,degree])
(2017 SR0)
|
半径r を持った球状にある2つのポイントの緯度経度を使うと、それらの大円距離を返します。オプションdegreeは緯度経度を単位として、度かラジアンのどちらを使うかを決定します。(デフォルトは度) サンプル:
-
HaversineDistance(120, 30, 0, -60, 5000) は 11388.7402734106を返します。
|
| int(x)
|
double型のxを取り、切り捨て整数値を返します。 サンプル:
-
int(7.9) は 7を返します。
-
int(col(a)) はcol(a)の切り捨て整数値を返します。
|
| ln(x)
|
xの自然対数を返します。
|
| ln1p(x)
|
xが1に非常に近いときのxの自然対数を返します。
|
| log(x)
|
xの底10のxの対数を返します。
|
| mod(n, m)
|
整数nを整数mで割った時の整数の剰余(0に丸めた商)を返します。 サンプル:
-
mod(16,7) は 2を返します。
-
mod(col(a),col(b))col(a) の値をcol(b)の値で割った整数の剰余を返します。
|
| mod2(n,m)
|
整数nを整数mで割った時の整数の剰余(負の無限大への丸めの商)を返します。係数の計算に使用される の商は の商は で丸められます。入力が負の場合、mod(の商を0への丸めで計算)と異なる値を返します。サンプル: で丸められます。入力が負の場合、mod(の商を0への丸めで計算)と異なる値を返します。サンプル:
-
mod(5,-3) は -1を返します。
-
mod(col(a),col(b)) col(a) の値をcol(b)の値で割った整数の剰余を返します。
|
| nint(x)
|
double型のxを取り、最近接整数に丸めます。 nint(x) 関数は round(x, 0) と同じ結果を返します。
|
| permut(n, k)
(2019 SR0)
|
与えられたn要素の集合から、指定されたk要素の置換の数を返します。 サンプル:
|
| prec(x, n)
|
値またはデータセットをとり、有効数字nで返します。 サンプル:
-
x = 1234567; prec(x, 3) は 1230000を返します。
-
prec(col(b), 3) 有効数字3桁のcol(b)の値を返します。
|
| product(vd)
|
vdのすべての数値を乗算し、積を返します。 サンプル:
|
| rmod(x, y)
|
Double型の値xをdouble型の値yで割った時のdouble型の値の剰余(0に丸めたsyouxをdouble型の値yで割った時のdouble型の値の剰余(0に丸めた商)を返します。  の商は の商は の丸めです。サンプル: の丸めです。サンプル:
-
rmod(4.5, 2) は 0.5を返します。
-
rmod(col(a),3) col(A)を3で割ったrmodを返します。
|
| rmod2(x, y)
|
double型の値xをdouble型の値yで割った時のdouble型の値の剰余(負の無限大への丸めの商)を返します。 の商はの丸めです。サンプル:
-
rmod2(-4.5, 2) は 1.5を返します。
-
rmod(col(a),3) col(A)を3で割ったrmod2を返します。
|
| round(x, n)
|
値またはデータセットをとり、小数点以下桁数nで返します。 Note: Origin 9.1 より新しい端数処理アルゴリズムを導入しています。システム変数@RNAは新旧メソッドを切り替えます。(旧メソッド@RNA=0、新メソッド@RNA=1(デフォルト))サンプル:
-
round(1.156, 1) は 1.2を返します。
-
round(col(a),2) 小数点以下2桁で四捨五入されたcol(a)の値を返します。
|
| sign(x)
|
実数 x をとり、符号を返します。 X>0 の場合、1を返します。x<0 の場合、-1を返し、x=0 のとき、0を返します。
|
| sqrt(x)
|
double型のxを取り、平方根を返します。
|
| Derivative(vd[,n])
|
ベクトル型 vd をとり、データリストの導関数を返します。 スムージングは無効です。オプションnで次数を指定します。(デフォルトは1です。)
|
| DerivativeXY(vx, vy [, n])
|
vxとvyの2つのベクトルを取り、曲線の導関数を返します。 オプションnで次数を指定します。(デフォルトは1です。)
|
| Integral(integrand,lowerlimit,upperlimit[, arg1, arg2, ...])
|
1つの次元積分値を実行し、以下の積分値を返します。
dt")
|
| Integrate(vd)
|
曲線下の面積積分を行います。 台形公式を使用します。
|
| IntegrateXY(vx, vy)
|
曲線(vx,vy)下の面積積分を行います。 ベクトルvxは曲線のx座標を含み、vyはy座標を含みます。
|
| Interp(x,vX,vY[,method,bound,smooth,extrap])
(2015 SR0)
|
x座標vxとy座標vyをとり、与えられた座標xにおいてy座標を補間/補外します。オプションmethod=0(線形、デフォルト)、1(3次スプライン)、2(3次Bスプライン)、3(Akima スプライン)method = 1のとき、bound は0 (自然) または 1 (not-a-knot)method=2 のとき、smooth=スムージング因子(負ではない)オプションextrapは、X値が参照範囲の外にあるときに適用されます。0(デフォルト)=最後の2点を使用してYを補外、1=全てのYを欠損値としてセット、2=最も近い入力XのY値を使用。
|
| permutationa(n, k)
(2019 SR0)
|
与えられたn個の要素の集合から、指定されたk個の要素についての(反復を伴う)置換の数を返します。サンプル:
-
permutationa(4, 2) は 16を返します。
|
特別な数学関数
| 名前
|
説明
|
| beta(a, b)
|
パラメータaとbを持つベータ関数
=\int_{0}^{1}t^{a-1}(1-t)^{b-1}")
|
| incbeta(x, a, b)
|
パラメータx,a,bを持つ不完全ベータ関数
=\int_{0}^{x} t^{a-1}(1-t)^{b-1}dt")
|
| incf(x, m, n)
|
不完全Fテーブル関数。 パラメータxは、積分範囲の上限、パラメータmは、分子分散の自由度、パラメータnは分母分散の自由度。
|
| incgamma(a,x)
|
パラメータaでxでの不完全ガンマ関数を計算。
=P\left( a, x\right)=\frac{1}{\Gamma \left( a\right)}\int _0^x t^{a-1}e^{-t}\,dt")
ここで") はaにおけるGamma関数の値。a > 0 かつ x ≥ 0 はaにおけるGamma関数の値。a > 0 かつ x ≥ 0
|
| inverf(x)
|
xでの逆誤差関数を計算
|
| j0(x)
|
0次のベッセル関数
|
| j1(x)
|
1次のベッセル関数
|
| jn(x, n)
|
n次のベッセル関数
=(x/2)^{n}\sum_{k=0}^{\infty} \frac{(-1)^{k}(x/2)^{2k}}{k!\Gamma(k+n+1)}")
ここで はgammaln(x)関数 はgammaln(x)関数
|
| y0(x)
|
0次の第二種ベッセル関数
|
| y1(x)
|
1次の第二種ベッセル関数
|
| yn(x, n)
|
n次の第二種ベッセル関数
=\lim_{v \rightarrow n} Y_n(v, n)")
ここで
=\frac{J_{n}(x,v)\cos(v\pi)-J_{n}(x,-v)}{sin(v\pi)}")
|
三角関数/双曲線関数
| Note: 角度の単位(ラジアン、度、グラジアン)は、system.math.angularunits プロパティに依存します(メインメニューの環境設定:オプション:数値フォーマット)
|
| 名前
|
説明
|
| acos(x)
|
xの逆余弦を返します。 x < -1 または x > 1 の場合、欠損値 ("--") を返します。
|
| acosh(x)
|
xの逆双曲線余弦の値を返します。 x < 1 の場合、欠損値 ("--") を返します。
|
| acot(x)
|
xの逆余接を返します。 入力xはどんな値でもとれます。第一または第二象限の値を返します。
|
| acoth(x)
|
|x| > 1 の逆双曲線余接の値を返します。
|
| acsc(x)
|
|x| の逆余割の値を返します。|x| < 1 の場合、欠損値("--")を返します。第一または第四象限の値を返します。
|
| acsch(x)
|
xの逆双曲線余割の値を返します。 x = 0 または x > ~3E153 の場合、欠損値("--")を返します。
|
| angle(x, y)
|
原点(0,0)と座標(x,y)を結ぶ線と正のx軸の値の角度(ラジアン)を返します。
|
| Angleint1(px1, py1, px2, py2 [, unit, direction])
|
対のx,y座標をとり、2点とX軸によって定義される線間の角度を返します。 オプションunitは、0=ラジアン(デフォルト)、1=度 を制御し、オプションdirectionは0(デフォルト)は第一(+x,+y)と第四(+x.-y)象限に角度値を返し、1は0-2pi ラジアンまたは0-360度の値を返します。サンプル:
-
angleint1(1,1,3,3,1) は 45を返します。
-
angleint1(col(a),col(b),col(c),col(d),1,1) 2組のXY座標とX軸で定義された直線の間の角度を(0 - 360)の度数で返します。
|
| Angleint2(px1, py1, px2, py2, px3, py3, px4, py4 [, unit, direction])
|
(px1, py1)と(px2, py2)を結ぶ線と、(px3, py3)と(px4, py4)を結ぶ別の線の2つの線の間の角度を返します。 オプションunit=0(デフォルト)でラジアンを、unit=1で度を返します。オプションdirectionは返す値の方向を指定します。オプションdirection=0(デフォルト)の場合、第一象限(+x.+y)と第四象限(+x,-y)に制限、direction=1の場合、0-2pi ラジアンまたは0-360の値を返します。サンプル:
-
angleint2(0,0,1,0,0,1,0,0,1,1) は 90を返します。
-
angleint2(col(a),col(b),col(c),col(d),col(e),col(f),col(g),col(h),1,1) 2組のxy座標で定義される線とX軸の間の角度 (0 - 360) を返します。
|
| asec(x)
|
xの逆正割を返します。 |x| < 1 の場合、欠損値("--")を返します。第一または第二象限の値を返します。
|
| asech(x)
|
xの逆双曲線正割の値を返します。0 < x ≤ 1 です。他のxの場合には欠損値("--")を返します。
|
| asin(x)
|
xの逆正弦を返します。-1 ≤ x ≤ 1 です。他のxの場合には欠損値("--")を返します。
|
| asinh(x)
|
x(実数)の逆双曲線正弦を返します。
|
| atan(x)
|
x(実数)の逆正接を返します。
|
| atan2(y,x)
|
座標 x,y (double型) をとり、正のX軸と点(x,y) の間の角度を返します。atan(x) 関数の変化形です。-π と π の間の値を返します。角度は半時計回り方向(y>0)に対して正で、時計回り方向(y<0)に対して負となります。
|
| atanh(x)
|
xの逆双曲線正接の値を返します。-1 < x < 1 です。他のxの場合には欠損値("--")を返します。
|
| cos(x)
|
xの余弦を返します。
|
| cosh(x)
|
xの双曲線余弦の値を返します。
|
| cot(x)
|
xの余接を返します。
|
| coth(x)
|
xの双曲線余接の値を返します。 xは0ではない値です。おおよそ 絶対値 > 710 では、欠損値("--")を返します。
|
| csc(x)
|
xの余割を返します。 x = 0 の場合、欠損値("--")を返します。
|
| csch(x)
|
xの双曲線余割の値を返します。 xは0ではない値です。おおよそ x > 710 のときには欠損値("--")を返します。
|
| Degrees(angle)
|
ラジアンのangleをとり、度を返します。
|
| Radians(angle)
|
度のangleをとり、ラジアンを返します。
|
| secant(x)
|
xの正割を返します。 Note:日付の秒の値を返すsec()関数と混同しないように注意してください。
|
| sech(x)
|
xの双曲線正割の値を返します。 おおよそ 絶対値 > 710 では、欠損値("--")を返します。
|
| sin(x)
|
xの正弦を返します。
|
| sinh(x)
|
xの双曲線正弦の値を返します。
|
| tan(x)
|
xの正接を返します。
|
| tanh(x)
|
xの双曲線正接の値を返します。
|
日付と時間の関数
Note: Origin 2019以降 、Originには3つの日時システムがあります。古くからのデフォルトのシステムは、Originの日付と時間で説明されているように、調整済みのユリウス日システムです。次の例は、長期的なデフォルトの日時スキームに依存しており、 "Julian-date value"が表示されている場合、Originの調整日の値を参照します。これらの機能は、代替システムで動作するはずです...
date2str(today(), "MM/dd/yyyy")$ = 09/27/2018 // default date-time system, @DS=0
date2str(today(), "MM/dd/yyyy")$ = 09/27/2018 // "2018" system, @DS=2018
...ただし、カレンダーの日付と同じ数値は、システムによって異なります。
date(9/27/2018) = 2458388 // デフォルトの日付と時間システム
date(9/27/2018) = 269 // 「2018」システム @DSP=2018
Originの代替日時スキームについては、Originの代替日時システムを参照してください。
| 名前
|
説明
|
| AddDay(vv)
(2021)
|
時間ベクトルvvを取り、24時間後に時間が経過すると、追加された日データを返します。サンプル:
-
addday(col(A)) 時刻データに日付情報を追加し、日付と時刻のデータを返します。
|
| Date(MM/dd/yyHH:mm:ss.##[,format$])
|
日付-時間の文字列をとり、ユリウス通日の値を返します。 format$が指定されていない場合、文字列はシステムのshort date フォーマットを使用して補間されます。format$文字列を指定せずに、1=デフォルト(MM/dd/yyyy),2(dd/MM/yyyy),3(yyyy/MM/dd) をとって最初の引数の日付フォーマットを制御します。サンプル:
-
date(24-09-2009,"dd-MM-yyyy") は 2455098を返します。
-
date(3/5/14)は 2456721 (US)を返しますが、date(5/3/14)は 2456721 (UK)を返します。
-
date(2/1/1986 13:13, 2)は 2446432.5506944を返しますが、 date(2/1/1986 13:13, 1) は 2446462.5506944を返します。
-
date(col(a)) col(a)の日付時刻文字列のユリウス通日値を返します。
|
| Date(yy,MM,dd)
|
年として double型 yy、月として MM、日として dd をとり、ユリウス通日の値を返します。 サンプル:
-
date(20,8,31)は2459092を返します。
|
| Date2str(d,format$)$
|
ユリウス通日の値をとり、日付文字列を返します。 サンプル:
-
date2str(2456573.123, "dd/MM/yyyy HH:mm")$ は 08/10/2013 02:57を返します。
-
date2str(col(b), "dd/MM/yyyy HH:mm")$ "dd/MM/yyyy Hh:mm” 形式でデータ文字列を返します。
|
| DatePart(datepart$, d [, n])
(2016 SR1)
|
ユリウス通に値(double型)dを取り、double型としてdatepart$で指定された一部日にちを返します。オプションnで週の始まりdatepart$=w または wwを指定します。 サンプル:
-
datepart("yyyy", 2457360.5107885) は 2015を返します。
-
datepart("yyyy", A) 列Aの日時データの年部分を返します。
-
datepart("y", Today())=;現在の年の日にちを返します。 (例:today() = 2457363 = 12/7/2015 = 341)
-
datepart("w", 2457360.5107885, 1)=;は 6を返しますが、 datepart(w, 2457360.5107885)=; は 5を返します。
|
| Day(d[,n])
|
ユリウス通日の値をとり、日数を返します。 オプションn=1 の場合、1から31(月)を返します。n=2のとき、1から366(年)を返します。例:
- (
Day(2454827.5982639, 2) は 362 を返します。
-
day(col(b),1) ユリウス通日をとり、曜日を返します。
|
| Hour(d)
|
ユリウス通日の値をとり、整数として時間を返します。 0から23(0=12:00 A.M. , 23=11:00 P.M.)の値を返します。例:
-
Hour(0.6997854) は 16を返します。
-
hour(col(b)) col(b)のユリウス通日値からの時間を返します。
|
| Minute(d)
|
ユリウス通日の値をとり、整数として時間を返します。(0から59) サンプル:
-
Minute(2454827.5982639) は 21を返します。
-
minute(col(b)) col(b)のユリウス通日値から分を返します。
|
| Month(d)
|
ユリウス通日の値をとり、整数として月を返します。(0から12) サンプル:
-
month(2454821) は 12を返します。
-
month(col(b) ユリウス通日の月をcol(b)で返します。
|
| MonthName(d[,n])$
|
ユリウス通日の値をとり、月名を返します。 月のフォーマットはオプションnで決まります。1=単一文字、3=3文字(デフォルト)、0=全て、-1=言語設定に関わらず英語の3文字です。例:
-
MonthName(2454827.5982639, 0)$ は Decemberを返します。
-
monthname(col(b),0)$ col(b)のユリウス通日値の完全な月名を返します。
|
| Now()
|
現在の日付/時刻を日付(ユリウス通日)の値として返します。 サンプル:
-
time2str(now()-date(col(a)),"HH:mm")$は現在の時刻とcol(a)のユリウス通日間の経過時間文字列(HH:mm) を返します。
|
| Quarter(d)
|
ユリウス通日をとり、四半期を返します。 サンプル:
-
Quarter(2454829.5745718) は 4を返します。
-
quarter(col(b)) col(b)のユリウス通日の四半期を返します。
|
| Second(d[,n])
|
ユリウス通日値または実数を受け取り、0 ~ 59.9999の範囲の実数として秒を返します。オプションn = 0は3桁以上の10進数字を表示しますが、ユリウス暦の日付の精度は4桁目の小数点以下を四捨五入すると0.0001秒に制限されます。 サンプル:
-
second(2454827.5982639) は 30.001を返します。
-
second(2454827.5982639, 0) は 30.000942349434を返します。
-
second(A) col(a)のユリウス通日の秒数を返します。
|
| Time(HH,mm,ss) と Time(HH:mm:ss[,Format$])
|
Hh,mm,ss またはカスタム日付/時間文字列(HH:mm:ss=デフォルト)をとり、ユリウス通日の値を返します。オプションFormat$引数は、カスタム文字列フォーマットを指定します。サンプル:
-
time(20:50:25)は0.8683449を返し、 time("2 20,50,25", "DDD hh,mm,ss") は 2.8683449を返します。
-
time(col(a))は、col(a)の時間データフォーマットを HH:mm:ss としてユリウス通日を返します。
|
| Time2str(d,format$)$
|
ユリウス通日をとり、指定されたフォーマットの時間文字列を返します。 サンプル:
-
time2str(0.1875, "HH:mm")$ は 04:30を返します。
-
time2str(col(b),"DDD:HH")$ DDD:HH形式の時刻文字列を返します。
|
| Today()
|
現在の日付をユリウス通日の値として返します。
|
| UnixTime(d1[, d2, n])
(2021)
|
Unixタイムスタンプ値とユリウス日値の間で変換します。オプションのパラメータn = 0(デフォルト)の場合、d1(Unixタイムスタンプ)をユリウス日に変換します。 n = 1の場合、d1(ユリウス日)をUnixタイムスタンプに変換します。オプションのパラメータd2はタイムゾーンオフセットです。ユリウス日をUnixタイムスタンプに変換するときは、両方 のオプションのパラメーターを指定する必要があることに注意してください(オフセットがない場合、d2 = 0)。Unix タイムスタンプの単位は秒です。サンプル:
-
unixtime(0) 調整済みのユリウス日値2440587を返します。
-
unixtime(2459011.27604,0,1) はUnixタイムスタンプ 1591857450を返します。
|
| WeekDay(d[,n])
|
ユリウス通日をとり、曜日を返します。 オプションnは週の始まりと終わりの値を指定します。0(デフォルト)=日曜(0-6)、1=日曜(1-7)、2=月曜(0-6)、3=月曜(1-7)サンプル:
-
weekday(2454825, 1) は 5を返します。
-
weekday(col(b)) col(b)のユリウス通日値を取得し、曜日を数値で返します。
|
| WeekDayName(d[,n1,n2])$
|
ユリウス通日(時間を含む)または、n2で定義された値をとり、平日を返します。 オプションn1は出力文字列の長さを制御します。-1=3文字を大文字表記、0=全てを表記し1文字目のみ大文字、1=1文字を大文字表記、3=3文字を表記し、1文字目のみ大文字。オプションn2で、週の開始と終了を指定します。0 = 0(日曜) - 6(土曜); 1 = 1(日曜) - 7 (土曜); 2 = 0(月曜) - 6(日曜); 3(デフォルト) = 1(月曜) - 7(土曜)。例:
-
WeekDayName(2454825,-1,0)$ は THUを返します。
-
weekdayname(col(b),3,0)$ 3文字の曜日名を1文字目大文字でフォーマットして返します。
|
| WeekNum(d[,n])
|
ユリウス通日の値をとり、年を通した週数を返します。(1から53) 週の始まり(日曜か月曜)を定義するオプションがあります。例:
-
weeknum(date(1/11/2009)) は 3を返します。
-
weeknum(date(col(c))) "MM/dd/yyy"(col(c))形式の日付データの列を取得し、date()関数を使用してユリウス日付値として解釈し、weeknum()関数を使用して週番号を返します。
|
| Year(d)
|
ユリウス通日の値をとり、整数として年を返します。(0100から-9999) サンプル:
-
year(2454821) は 2008を返します。
-
year(date(col(c))) "MM/dd/yyyy"(col(c))形式の日付データの列を取得し、date()関数を使用してユリウス日付値として解釈し、4桁の年を返します。
|
| YearName(d[,n])$
|
ユリウス通日の値をとり、文字列として年を返します。 オプションnで文字列のフォーマットを指定し、0=2桁、1(デフォルト)=2桁(アポストロフィ付)、2=4桁 です。サンプル:
-
YearName(2454827.5982639, 1)$ は '08を返します。
-
yearName(date(col(c)),0)$"MM/dd/yyyy" (col(c))形式の日付データの列を取得し、date()関数を使用してユリウス日付値として解釈し、2桁の年を返します。
|
論理関数
| 名前
|
説明
|
| if(con,val_true[,val_false])[$]
(2019 SR0)
|
条件式conを評価し、比較がTRUEの場合はval_true、偽の場合はval_falseを返しますサンプル
-
if(A>B,1,0) col(A)>col(B)の場合は1を返し、そうでない場合は0を返します。
-
if(A$==B$,1,0)col(A)の文字列がcol(B)の文字列と一致する場合は1を返し、そうでない場合は0を返します。
-
if(A==1,100," ") col(A)[i] = 100の場合は100を返し、そうでない場合はセルを空白のままにします。
|
| ifs(con1,val1[,con2,val2,]...[,con40,val40])[$]
(2019 SR0)
|
複数の条件 con n を評価し、最初のTRUE条件の対応する d / str を返します。サンプル
Ifs(A>0.5,"Large",A<0.3,"Small",1,"Other")$ col(A)の値が0.5より大きい場合、Largeを返し、0.3より小さい場合はSmallを返し、その間の残りの場合はOtherを返します。
|
| ifna(val,val_na)[$]
(2019 SR0)
|
指定された数式valを計算し、結果がない場合は指定された文字列/数値val_naを返し、そうでない場合はvalの結果の文字列/数値表示を返します。サンプル
-
IfNA(col(A)/col(B),"not found")$col(A)/col(B) が見つからない場合は"Not found"を返し、見つからない場合はcol(A)/col(B) の文字列表示を返します。
|
| switch(expression,val1,res1[,val2,res2]...[,val39,res39][,default])[$]
(2019 SR0)
|
値のセットvalを使用して値式を評価し、一致する値valnがあれば、対応するresnを返します。サンプル
-
switch(A,1,"A1",2,"B1",3,"C1","Other")$
|
信号処理関数
| 名前
|
説明
|
| fftamp(cx [,side])
(2015 SR1)
|
複素ベクトルcx(通常FFTの複素結果)をとり、振幅を返します。オプションsideは、出力スペクトルを定義します(1=片側、2=両側とシフト)。サンプル:
-
fftamp(fftc(col(B)), 2) 入力信号のFFT複素数結果の振幅(両側)をB列に返します。
-
col(C) = col(B)-mean(col(B)); fftamp(fftc(col(C))) DCオフセットを除去した振幅結果を返します(片側)。
|
| fftc(cx)
(2015 SR1)
|
ベクトル型 cx をとり、複素FFT結果を返します。出力列のデータ型をcomplex(16)にする必要があります。 例:
-
fftc(col(B)) 入力信号列BのFFT複素結果を返します。
-
fftc(rSignal) 範囲変数rSignalの入力信号のFFT複素結果を返します。
|
| fftfreq(time, n[, side , shift])
(2015 SR1)
|
サンプリング間隔timeと信号サイズnをとり、FFT結果の周波数を返します。オプションsideは、出力スペクトルを定義し(1=片側、2=両側)、shiftは両側のときにシフトするかを定義します。(0=シフトなし、1=シフト) サンプル:
-
fftfreq(0.001, 100) 0から500までのデータセットを、間隔10(片側、シフトなし)で返します。
-
fftfreq(0.01, 100, 2, 1) サンプリング間隔0.01の両側シフト周波数を返します。
|
| fftmag(cx [,side])
(2015 SR1)
|
複素ベクトルcx(通常FFTの複素結果)をとり、マグニチュードを返します。オプションsideは、出力スペクトルを定義します。(1=片側、2=両側とシフト) サンプル:
-
fftmag(fftc(col(B)), 2) 入力信号のFFT複素数結果のマグニチュード(両側)をB列に返します。
-
col(C) = col(B)-mean(col(B)); fftmag(fftc(col(C))) DCオフセットを除去したマグニチュード結果を返します(片側)。
|
| fftphase(cx[, side, unwrap, unit])
(2015 SR1)
|
複素ベクトルcx(通常FFTの複素結果)をとり、位相を返します。オプションsideは、スペクトルの出力を定義(1=片側、2=両側とシフト)します。unwrapは位相角度の巻きの有無を(0=巻き、1=巻きなし)、unitは単位を定義します(0=ラジアン、1=度)。 サンプル:
-
fftphase(fftc(col(B))) 入力信号のFFT複素数結果の位相(片側、巻きなし、度単位)をB列に返します。
-
fftphase(fftc(col(B)), 2, 0, 0) 入力信号のFFT複素数結果の位相(両側、巻きあり、ラジアン単位)を列Bに返します。
|
| fftshift(cx)
(2015 SR1)
|
複素ベクトルcx(通常FFTの複素結果または周波数)をとり、シフトされたベクトルを返します。出力列のデータ型をcomplex(16)にする必要があります。 サンプル:
-
fftshift(fftc(col(B))) シフトされた複素数ベクトルを返す
|
| ifftshift(cx)
(2015 SR1)
|
複素ベクトルcx(通常FFTの複素結果またはシフトされたFFT結果)をとり、シフトされていないベクトルを返します。出力列のデータ型をcomplex(16)にする必要があります。 サンプル:
-
ifftshift(col(B)) シフトされていないベクトルを返します。列Bにはシフトされた複素数ベクトルが含まれています。
|
| invfft(cx)
(2015 SR1)
|
複素ベクトルcx(通常FFTの複素結果)をとり、逆FFT結果を返します。出力列のデータ型をcomplex(16)にする必要があります。 サンプル:
-
invfft(ifftshift(col(B))) 列BのシフトFFT複素結果の逆FFTを返します。
|
| windata(type, n)
(2015 SR1)
|
type(ウィンドウ法)とn(ウィンドウサイズ)の整数をとり、サイズnのベクトルとしてウィンドウの信号を返します。サンプル:
-
windata(2, 50) ベクトルサイズ50 の三角ウィンドウの信号を返します。
|
基本統計関数
| 名前
|
説明
|
| Count(vd[,n])
|
ベクトル型 vd をとり、要素の数を返します。 オプションのnで要素を指定します。0 (デフォルト) = 全て; 1 = 数値; 2 = 欠損値 です。サンプル:
-
count(col(a),2) は 22 と欠損値の数を返します。
-
count(col(a),3) は155 と欠損値の数を返します。
|
| Max(vd)
|
ベクトル型 vd をとり、最大値を返します。 サンプル:
-
max(col(A)) col(a)での最大値を返します。
-
max(1,2,3,4,9) は 9を返します。
|
| Mean(vd)
|
ベクトル型 vd をとり、平均を返します。 サンプル:
-
mean(col(A)) col(A)の平均値を返します。
Note: 複数データセットの平均を行で計算する場合は、シンタックスsum(vd)_meanを使用します。
-
sum(A:D)_mean 列Aから列Dまでの平均を行で計算
詳細は、sum(vd)関数を参照してください。
|
| Median(vd[,method])
|
ベクトル型 vd をとり、中央値を返します。 オプションmethodで補間方法を指定します。0 (デフォルト) = 経験分布の平均; 1 = 近傍法; 2 = 経験分布; 3 = 加重平均右; 4 = 加重平均左; 5 = Tukey hinge です。サンプル:
-
median(col(A),2)中 央値を返します(n = 2で決定される)。補間手法についての詳細情報は、分位数の補間をご覧ください。
|
| Min(vd)
|
ベクトル型 vd をとり、最小値を返します。
|
| Ss(vd [,ref])
|
ベクトル型 vd をとり、平方和を返します。 平方和は、いくつかの参照値 ref を vd の各値から減算したあと計算されます。オプションrefはvdの平均をデフォルトとしますが、refは定数やデータセット、関数にすることもできます。例:
-
ss(vd) は、平均を減算した平方和を返します。
-
ss(vd,4) vdの各要素から4を引いた後計算された平方和を返します。
-
ss(vd1,vd2) vd1の各要素からvd2 を引いた後計算された平方和を返します。
-
AA = 1; BB = 2; ss(vd, AA+BB*x) vdから1+2xで説明される行の減算後に平方和を返します。
|
| StdDev(vd)
|
ベクトル型 vd をとり、標本標準偏差を返します。サンプル:
-
StdDev(col(A)) 標本標準偏差を返します。
|
| StdDevP(vd)
|
ベクトル型 vd をとり、母標本標準偏差を返します。サンプル:
-
StdDevP(col(A)) 母標準偏差を返します。
|
| Sem(vd)
(2020b)
|
ベクトル型 vd をとり、標準誤差を返します。サンプル:
|
| Total(vd)
|
ベクトル型 vd をとり、要素の合計を返します。サンプル:
-
total(col(a)) 列Aのすべてのデータポイントの合計を返します。
|
| averageif(vd, con$)
|
ベクトルvdと条件con$をとり、con$を満たす値の平均を返します。サンプル:
-
col(A) = data(1,32); con$ = col(A) > 5 && col(A) < 10; averageif(col(A), con$)=; は 7.5を返します。
|
| Countif(vd,con$)
|
ベクトル型 vd をとり、条件 con$ を満たす値のカウントを返します。条件 con$ は二重引用符("")で囲む必要があります。
-
countif(col(b),"col(b)>0")=;
-
countif(col(A),"col(A)<10 && col(A)>5")=;
|
| Maxifs(vd,con$)
|
ベクトル型 vd をとり、条件 con を満たす最大値を返します。サンプル
-
maxifs(col(A), "col(A)>5") は、col(A)の部分集合の最大値を5より大きく返します。
|
| Minifs(vd,con$)
|
ベクトル型 vd をとり、条件 con を満たす最小値を返します。サンプル
-
minifs(col(A), "col(A)>5") は、col(A)の部分集合の最小値を5より大きく返します。
|
| sumif(vd,con$)
|
ベクトル型 vd をとり、条件 con$ を満たす値の合計を返します。
|
統計関数
| 名前
|
説明
|
| Correl(vx, vy)
|
データセットvxとvyをとり、相関係数を返します。サンプル:
-
for(ii=1;ii<=30;ii++) col(1)[ii] = ii; col(2)=ln(col(1)); correl(col(A),col(B))=; は 0.92064574677971を返します。
|
| cov(vx, vy[, avex, avey])
|
データセット vx と vy 、それぞれの平均 avex と avey をとり、 共分散を返します。 サンプル:
-
for(ii=1;ii<=30;ii++) col(1)[ii] = ii; col(2)=ln(col(1)); cov(col(A),col(B))=; は 6.8926313172818を返します。
|
| Forecast(x,vx,vy)
|
x座標をvxとy座標でvyとし、線形回帰を実行して、与えられた座標xでy座標を計算または予測します。
|
| Intercept(vx,vy)
|
vx(独立)とvy(従属)の2つのベクトルを取り、線形回帰の切片を返します。
|
| mae(vobs,vpred)
(2023b)
|
2つのベクトル、vobs(実測)とvpred(推測)をとり、平均絶対誤差を返します。
|
| mbe(vobs,vpred)
(2023b)
|
2つのベクトル、vobs(実測)とvpred(推測)をとり、平均バイアス誤差を返します。
|
| rms(vd)
|
ベクトル型 vd をとり、二乗平均平方根返します。
|
| rmse(vobs,vpred)
(2023b)
|
2つのベクトル、vobs(実測)とvpred(推測)をとり、二乗平均平方根誤差を返します。
|
| Slope(vx,vy)
|
vx(独立)とvy(従属)の2つのベクトルを取り、線形回帰の傾きを返します。
|
| ave(vd, size[, stats])
|
ベクトルvdをとり、sizeの各グループの平均の範囲を返します。statsは、平均値でない他の統計値を出力するオプションを提供します。vdの要素がsizeの倍数でない場合、mod(vdSize,size)要素のみを平均した値を返します。サンプル:
-
ave(col(a),5) はcol(a) をサイズ 5 のグループに分け、各グループの平均を計算します。
-
ave(A,5,2) はcol(a) をサイズ 5 のグループに分け、各グループのSDを計算します。
|
| diff(vd[,n])
|
ベクトルvdをとり、隣接要素間の相違の範囲を返します。返された範囲の最初の要素は vd(i+1)-vdiなどです。オプションのパラメータnの値に応じて、N-1、N、またはN + 1要素を返します。
- 0 =(デフォルト)、N-1要素を返します。
- 1 =データセット終了時に0でパッドし、N個の要素を返します。
- 2 =データセット開始時に0でパッドし、N個の要素を返します。
- 3 =データセット開始時に0でパッドし、要素N + 1がN個の要素を合計して得られるN + 1要素を返します。
- 4 =データセット開始時にNANUMでパッドし、N個の要素を返します。
|
| sum(vd)
|
Sum() 関数には2つのモードがあります。
「列」モードでは、単一列のベクトルvdを取り、累積和の値(1からi、i = 1、2、...、N)を保持するベクトルを返します。i+1番目の要素は最初のi要素の合計です。返される範囲の最後の要素は、データセット内のすべての要素の合計です。サンプル:
「行」モードでは、2つ以上の列をとり、行ごとの合計値のベクトルを返します。構文のサフィックス_mean、_sd、<code>_median</code>、 _max、_min、_nで、行ごとの平均、標準偏差、中央値、最大値、最小値、数値の数を取得できます。サンプル:
-
sum(A:E) 列1から5の行ごとの合計値
-
sum(A:C, D:G, F) 列AからC、DからG、およびFの行ごとの合計値
-
sum(A2:D4)_mean A2からD4からなるブロックの行ごとの平均値を計算
Note: 値の設定とF(x)=でサポートされる「行」モードシンタックスは、スクリプトと異なり、互換性がありません。詳細は sum() 関数 を参照してください。
|
| Confidence(alpha, std, size[, dist])
|
有意水準 alpha、母標準偏差 std とサンプル size をとり、dist分布を使用した母平均の信頼区間を返します。サンプル:
-
confidence(0.05, 1.5, 100) は 0.29399459768101を返します。
|
| Geomean(vd)
|
ベクトル vd をとり、幾何平均を返します。
-
Geomean(col(A)) A列の幾何平均を返します。
|
| Geosd(vd)
|
ベクトル vd をとり、幾何標準偏差を返します。
-
Geosd(col(A)) A列の幾何標準偏差を返します。
|
| Harmean(vd)
|
ベクトル vd をとり、調和平均を返します。
-
Harmean(col(A)) A列の調和平均を返します。
|
| histogram(vd, inc, min, max)
|
ベクトル vd、ビンの幅 = inc、vd の最小min と vdの最大 max をとり、データビンを生成します。各ビン上限上のポイントは次のビンに含まれます。
|
| Kurt(vd)
|
ベクトル型 vd をとり、尖度を返します。サンプル:
-
dataset ds = {1, 2, 3, 2, 3, 4, 5, 6, 4, 8}; kurt(ds) は 0.39502164502164を返します。
|
| lcl(vd[, level])
|
ベクトル vdを取り、信頼水準levelでの下側信頼限界を返します。 サンプル:
-
lcl(col(A)) 信頼水準0.95での列Aの下側信頼限界を返します。
|
| Mad(vd)
|
ベクトル型 vd をとり、平均絶対偏差を返します。 サンプル:
-
mad(col(A))A列の平均絶対偏差を返します。
|
| Mode(vd)
|
ベクトル型vdをとり、vd内で最も頻度の高い数を返します。例:
aa = mode(col(A)) は、列Aで最も頻度の高い数を返します。
|
| Modes(vd)
|
ベクトル型vdをとり、vd内で最も頻度の高い数のベクトルを返します。例:
Col(B) = mode(col(A)) は、列Aから列Bで最も頻度の高い数を出力します。
|
| Percentile(vx, vy)
|
ベクトル型vxをとり、vyで指定された各値のパーセンタイル値を返します。 サンプル:
-
DATA1_A = normal(1000); DATA1_B = {1, 5, 25, 50, 75, 95, 99}; DATA1_C = percentile(DATA1_A, DATA1_B); 1%、5% ~ 99%の正規分布のパーセンタイルを含むデータセットDATA1_Cを返します。
|
| QCD2(n)
|
サンプルサイズ n をとり、品質管理D2係数を返します。サンプル:
|
| QCD3(n)
|
サンプルサイズ n をとり、品質管理D3係数を返します。係数D3は、X-R管理図における3シグマ下部管理限界です。サンプル:
|
| QCD4(n)
|
サンプルサイズ n をとり、品質管理D4係数を返します。係数D4は、X-R管理図における3シグマ上部管理限界です。サンプル:
|
| Skew(vd)
|
ベクトル型 vd をとり、歪度を返します。サンプル:
-
skew(col(a)) 列Aのデータセットの歪度を返します、
|
| ucl(vd[, level])
|
ベクトル vdを取り、信頼水準level(デフォルトは0.95)での上側信頼限界を返します。サンプル:
-
ucl(col(a)) 信頼水準0.95での列A の上側信頼限界を返します。
|
| Emovavg(vd,n[,method])
|
ベクトル型vd、整数 n = 時間幅をとり、指数移動平均を返します。オプションmethodで計算の開始位置を指定します。0 (デフォルト) = ポイントnから; 1 = ポイント1から。サンプル:
-
for(ii=1;ii<=30;ii++) col(1)[ii] = ii; col(3)=emovavg(col(1),10, 1); //method II 開始点=1を使用して計算された値を列3に入力します。
|
| Mmovavg(vd,n)
|
ベクトル型vd、整数 n = 時間幅をとり、修正移動平均を返します。サンプル:
-
for(ii=1;ii<=30;ii++) col(1)[ii] = ii; col(2)=mmovavg(col(1),10); 行10から始まる各ポイントの移動平均値を 列2 に入力します。
|
| Movavg(vd,back,forward[,missing])
|
ベクトルvd をとり調整した範囲[i-back, i+forward]の、i ポイントの移動平均を返します(i は現在の行番号)。オプションmissingで、欠損値を省略するか決定します。サンプル:
-
for(ii=1;ii<=10;ii++) col(1)[ii] = ii; col(2)=movavg(col(1),0, 2); これは、それぞれのポイントでの隣接平均をcol(2)に入力します。(Note that col(2)[9] = (col(1)[9]+col(1)[10])/2 and col(1)[10] = col(2)[10]).
|
| Movcoef(v1,v2,back,forward[,missing])
|
ベクトルv1 および v2をとり調整した範囲[i-back, i+forward]の、i ポイントの移動相関係数のベクトルを返します(i は現在の行番号)。オプションmissingで、欠損値を省略するか決定します。サンプル:
-
wcol(4) = MovCoef(wcol(2), wcol(3), 20, 0);
ウィンドウ[i-20. i]内のcol(2)とcol(3)の移動相関係数で4列目を埋めます。
|
| Movrms(vd,back[,forward])
|
ベクトルvd をとり調整した範囲[i-back, i+forward]の、i ポイントの二乗平均平方根を返します(i は現在の行番号)。 サンプル:
-
col(B)=movrms(col(A),0, 2); ウィンドウ[i,i+2])内のデータの各ポイントでcol(B)にRMSを入力します。
|
| Movslope(vx,vy[,n])
|
vx(独立)とvy(従属)の2つのベクトルを取り、各ポイントの移動傾きのベクトルを返します。オプション n はウィンドウ幅を指定します(>1)。nが偶数の場合、1を加えます。n を指定しない場合、入力の線形フィットの傾きの値を返します。サンプル:
-
col(C)=movslope(col(A),col(B),5); 各ポイントの傾きを列Cに返します(最初と最後のセルは欠損値になります)。
|
| Tmovavg(vd,n[,missing])
|
ベクトル型vd、整数 n = 時間幅をとり、三角移動平均を返します。オプションmissingで、欠損値を省略するか決定します。サンプル:
-
for(ii=1;ii<=30;ii++) col(1)[ii] = ii; col(2)=tmovavg(col(1),9); は、9行目から始まるそれぞれの値での三角移動平均値を2番目の列に数値を入れます。
|
| Wmovavg(vd,vw)
|
ベクトル型 vd (スムージングのためのデータ)、vw (インデックスされた重み付き因子)をとり、加重移動平均のベクトルを返します。サンプル:
-
for(ii=1;ii<=30;ii++) col(1)[ii] = ii; //data vector
for(ii=1;ii<=10;ii++) col(2)[ii] = ii/10; //weight vector
col(3)=wmovavg(col(1),col(2));
は、10行目から始まるそれぞれの値での加重移動平均値を3番目の列に数値を入れます。
|
分布関数
累積分布関数(CDF)
| 名前
|
説明
|
| betacdf(x,a,b[,tail])
|
パラメータ aと bを持つ xにおけるベータ累積分布関数を計算します。aとbはすべて正でなければならず、xは区間[0,1]上になければなりません。tailは返される確率が下側のtailまたはupper tailであることを決定します。
|
| binocdf(k,n,p)
|
二項分布で、n, p.に対応するパラメータを使って、与えられた値kでの上側確率/下側確率および点確率を計算します。
&=P(X\le k)=\sum_{i=0}^k P(X=i)\\&=\sum_{i=0}^k {n \choose k}p^i(1-p)^{n-i}\end{aligned}")
|
| bivarnormcdf(x,y,corre)
|
二変量正規分布の下側確率を計算します。
\\=\frac 1{2\pi \sqrt{1-\rho ^2}}\int_{-\infty }^y\int_{-\infty }^x\exp (\frac{x^2-2\rho XY+Y^2}{2(1-\rho ^2)})dXdY")
|
| chi2cdf(x,df[,tail])
|
自由度df を持つカイ二乗分布に対する下側確率を計算します。
|
| foldnormcdf(x,mu,sigma)
|
折り畳まれた正規分布の下側確率を計算します。
|
| fcdf(f,ndf,fdf[,tail])
|
f における分子ndf と分母の変数fdfの自由度の変数F累積分布関数を計算します。tailは返される確率が下側のtailまたはupper tailであることを決定します。
|
| gamcdf(g,a,b[,tail])
|
形状パラメータa とスケールパラメータ bを使用し、ガンマ変量g の自由度を持つガンマ分布の下側確率を計算します。tailは返される確率が下側のtailまたはupper tailであることを決定します。
|
| hygecdf(k,m,n,l)
|
対応するパラメータを使った超幾何分布で、与えられた値での下側確率を計算します。
&=P(X\leq k)=\sum_{i=0}^kP(X=i)\\&=\sum_{i=0}^k\frac {{m \choose i}{n-m \choose l-i} }{{n \choose l} }\end{aligned}")
ここで、n は母集団のサイズ、m は母集団の中で成功状態の数、l は引き分けのサンプル数です。
|
| landaucdf(x,mu,sigma[,tail])
(2024b)
|
位置パラメータmuとスケールパラメータsigmaを使用して、xにおけるランダウ分布の累積密度関数を計算します。 tailは、返される確率が下側か上側であるかを決定します。
|
| logncdf(x,mu,sigma[,tail])
(2015 SR0)
|
対応するパラメータmuおよびsigmaを使用してLognormal分布に関連付けられた、指定された値xの指定されたtail型テールの確率を計算します。tailが指定されていない場合、低いテール確率が返されます。tailが指定されていない場合、低いテール確率が返されます。
|
| ncbetacdf(x,a,b,lambda)
|
非心ベータ分布の下裾で累積分布関数を計算します。
&=P(B\leq \beta )\\&=\sum_{j=0}^\infty e^{-\lambda /2}\frac{(\lambda /2)^j}{j!}P_b(B\leq \beta )\end{aligned}")
ここで
=\frac{\Gamma (a+b)}{\Gamma (a)\Gamma (b)}\int_0^\beta B^{a-1}(1-B)^{b-1}dB") - これは、ベータ分布関数や不完全ベータ関数です。
|
| ncchi2cdf(x,f,lambda)
|
非心カイ二乗分布の下側確率を計算します。
\\=P(X\le x: \nu;\lambda)\\=\sum_{j=0}^\infty {e^{-\frac{\lambda}{2}}\frac{{(\lambda/2)}^j}{j!}P(X\le x:\nu+2j;0)}")
ここで、") は は 自由度の中央 自由度の中央 です。 です。
|
| ncfcdf(f,df1,df2,lambda)
|
非心ディガンマまたは分散比分布の下側確率を計算します。
=P(\digamma \leq f)") = =d\digamma") , ,
ここで
![\begin{aligned}P(\digamma )&=\sum_{j=0}^\infty e^{-\lambda /2}\frac{(\lambda /2)^j}{j!}\cdot\frac{(\nu _1+2j)^{(\nu _1+2j)/2}\nu _2^{\nu _2/2}}{B((\nu _1+2j)/2,\nu _2/2)}\\&\cdot u^{(\nu _1+2j-2)/2}\left[ \nu _2+(\nu _1+2j)u\right] ^{-(\nu _1+2j+\nu _2)/2}\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-eb25f9ef60abdee3860cc90749b36385.png "\begin{aligned}P(\digamma )&=\sum_{j=0}^\infty e^{-\lambda /2}\frac{(\lambda /2)^j}{j!}\cdot\frac{(\nu _1+2j)^{(\nu _1+2j)/2}\nu _2^{\nu _2/2}}{B((\nu _1+2j)/2,\nu _2/2)}\\&\cdot u^{(\nu _1+2j-2)/2}\left[ \nu _2+(\nu _1+2j)u\right] ^{-(\nu _1+2j+\nu _2)/2}\end{aligned}")
なお、") はβ関数です。 はβ関数です。
|
| nctcdf(t,df,delta[,maxiter])
|
非心のスチューデントt分布に対する下側確率を計算します。
=P(T\leq t)\\&=C_\nu \int_0^\infty (\frac 1{\sqrt{2\pi }}\int_{-\infty }^{\alpha u-\delta }e^{-x^2}dx)u^{v-1}e^{-u^2/2}du \end{aligned}")
with
2^{(\nu -2)/2}},\ \alpha =\frac t{\sqrt{\nu }},\ \nu >0")
|
| normcdf(x[,tail])
|
正規の累積分布に関連付けられた、指定された値xxの指定されたtail型テールの確率を計算します。
|
| poisscdf(k,lambda)
|
ポアソン分布で、lambda に対応するパラメータを使って、与えられた値 k での下側確率を計算します。
=\sum_{i=0}^kP(X=i)=\sum_{i=0}^ke^{-\lambda }\frac{\lambda ^k}{k!}")
|
| srangecdf(q,v,group)
|
スチューデント範囲統計分布の下側の裾に関連付けられた確率を計算します。
![\begin{aligned}P(q)&=C\int_0^{+\infty }x^{\nu -1}e^{-\nu x^2/2}\{r\int_{-\infty }^{+\infty }\Phi (y)\\&\cdot\left[\Phi (y)-\Phi (y-qx)\right]^{r-1}dy\}dx\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-dc1ee2849c312d0bd7590d480983ae0f.png "\begin{aligned}P(q)&=C\int_0^{+\infty }x^{\nu -1}e^{-\nu x^2/2}\{r\int_{-\infty }^{+\infty }\Phi (y)\\&\cdot\left[\Phi (y)-\Phi (y-qx)\right]^{r-1}dy\}dx\end{aligned}")
ここで
2^{\nu /2-1}}") , , =\int_{-\infty }^y\frac 1{\sqrt{2\pi }}e^{-t^2/2}dt")
|
| tcdf(t,df[,tail])
|
スチューデントt分布の累積分布関数に自由度dfを用いて指定されたtail型テールの確率を計算します。
|
| wblcdf(x,a,b)
|
パラメータaとbを使って、x値に対する下側ワイブル累積分布関数を計算します。
&=\int_0^xba^{-b}t^{b-1}e^{-(\frac ta)^b}dt\\&=1-e^{-(\frac xa)^b}I_{(0,+\infty )}(x)\end{aligned}")
ここで、}(x)") はWeibull CDFがゼロではない区間です。 はWeibull CDFがゼロではない区間です。
|
確率密度関数(PDF)
| 名前
|
説明
|
| betapdf(x,a,b)
|
パラメータ a と bを持つベータ分布の確率密度関数を返します。
=\frac{\Gamma (a+b)}{\Gamma (a)\Gamma (b)}B^{a-1}(1-B)^{b-1}")
 です。 です。
|
| binopdf(x,nt,p)
(2015 SR0)
|
パラメータ nt と pを持つ二項分布の確率密度関数を返します。
 = \left( \begin{matrix} nt \\ x \end{matrix}\right)
p^x (1-p)^{nt-x},")
ここで、 および および 
|
| cauchypdf(x,a,b)
(8.6 SR0)
|
コーシー確率密度関数 (別名ローレンツ分布)
![f(x| a, b) = \frac{1}{\pi b \left[1 + \left(\frac{x - a}{b}\right)^2\right]}
= { 1 \over \pi } \left[ { b \over (x - a)^2 + b^2 } \right]](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-8e85c2fcc57510fad5abdf7c7e52f68b.png "f(x| a, b) = \frac{1}{\pi b \left[1 + \left(\frac{x - a}{b}\right)^2\right]}
= { 1 \over \pi } \left[ { b \over (x - a)^2 + b^2 } \right]")
|
| exppdf(x,lambda)
(8.6 SR0)
|
Xの値で評価される速度パラメータλを持つ指数分布の確率密度関数を返します。
=\lambda e^{{-x}{\lambda}}, x \geq 0")
|
| foldnormpdf(x,mu,sigma)
|
平均 mu と標準偏差 sigma の折りたたまれた正規分布を使用して、Xの各値における確率密度関数を計算します。
 = \frac{1}{ \sqrt{ 2 \pi } \sigma} e^{ - \frac{(x - \mu)^2}{ 2 \sigma^2 } } + \frac{1}{ \sqrt{ 2 \pi } \sigma} e^{ - \frac{(x + \mu)^2}{ 2 \sigma^2 } }, x \geqslant 0, \; \sigma > 0")
|
| gampdf(x,a,b)
(8.6 SR0)
|
パラメータa およびb を持つガンマ確率密度を返します。
=\frac 1{b^a\Gamma (a)}x^{a-1}e^{\frac{-x}b}")
ガンマ分布のデータセットからスケールと形状パラメータのa とb を生成するには、推定関数gamfitを使用します。
|
| ks2d(vx, vy[,bandwidth, grid, interp, binned])
(2020)
|
指定された帯域幅法と密度法を使用して、ポイント (x, y) での2Dカーネル密度を返します。ここでvxはX座標値のベクトル、vyはY座標値のベクトルです。帯域幅法、グリッド(帯域幅法のみ)、補間、密度のオプション(interp = 1(true)の場合のみ適用可能)。
^2}{2w_x ^2} - \frac{(y-\text{vy}_i)^2}{2w_y^2} \right)")
ここでn はベクトルvx または vyの要素の数で、インデックスi はベクトルvx またはvy のi番目の要素、最適スケール(wx, wy)は推定関数kernel2widthで推定されます。
|
| ks2density(x,y,vx,vy,wx,wy)
(2015 SR0)
|
スケール(wx, wy)のデータセット (vx, vy)で確率される関数で(x, y)での2Dカーネル密度を返します
ここでn はベクトルvx または vyの要素の数で、インデックスi はベクトルvx またはvy のi番目の要素、最適スケール(wx, wy)は推定関数kernel2widthで推定されます。
|
| ksdensity(x,vx,w)
(2015 SR0)
|
バンド幅wのベクトルvxのxにおけるカーネル密度を返します。
=\frac{1}{ n\text{w} } \sum_{i=1}^n K \left( \frac{x-\text{vX}_i}{ \text{w} } \right)")
ここで、n はベクトルvXのサイズ、K はカーネル関数で、Originは通常 (ガウス) カーネル関数 =\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}}") を使用し、 を使用し、  はベクトルvXのi番目の要素です。 はベクトルvXのi番目の要素です。
|
| landaupdf(x,mu,sigma)
(2024b)
|
位置パラメータ mu とスケール パラメータ sigma をもつランダウ分布を使用して、x の各値における確率密度関数を計算します。
|
| lappdf(x,mu,b)
(8.6 SR0)
|
ラプラス確率密度関数
 = \frac{1}{2b} \exp \left( -\frac{|x-\mu|}{b} \right) \,\!")
![= \frac{1}{2b}
\left\{\begin{matrix}
\exp \left( -\frac{\mu-x}{b} \right) & \mbox{if }x < \mu
\\[8pt]
\exp \left( -\frac{x-\mu}{b} \right) & \mbox{if }x \geq \mu
\end{matrix}\right.](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-a5a9b7eb31d29b76b9351919882b5ec3.png "= \frac{1}{2b}
\left\{\begin{matrix}
\exp \left( -\frac{\mu-x}{b} \right) & \mbox{if }x < \mu
\\[8pt]
\exp \left( -\frac{x-\mu}{b} \right) & \mbox{if }x \geq \mu
\end{matrix}\right.")
|
| lognpdf(x,mu,sigma)
(8.6 SR0)
|
分布パラメータmu とsigma を持つ対数正規確率密度関数のXでの値を返します。
=\frac 1{x\sigma \sqrt{2\pi }}e^{\frac{-(\ln x-\mu )}{2\sigma ^2}}")
|
| normpdf(x,mu,sigma)
(8.6 SR0)
|
平均 mu と標準偏差 sigma の正規分布を使用して、Xの各値における確率密度関数を計算します。
=\frac 1{\sigma \sqrt{2\pi }}e^{\frac{-(x-\mu )^2}{2\sigma ^2}}")
|
| poisspdf(x,lambda)
(8.6 SR0)
|
lambdaでの平均値パラメータを使って、Xの各値のポアソン確率密度関数を計算します。
=\frac{\lambda ^x}{x!}e^{-\lambda }I_{(0,1,...)}(x)")
|
| wblpdf(x,a,b)
(8.6 SR0)
|
パラメータ a と bを持つワイブル分布の確率密度関数を返します。
=ba^{-b}x^{b-1}e^{-(\frac xa)^b}")
ワイブル分布のデータセットからスケールと形状パラメータのa とb を生成するには、推定関数wblfitを使用します。
|
逆累積分布関数(INV)
| 名前
|
説明
|
| betainv(p,a,b)
|
指定したベータ分布の逆累積分布関数を返します。
|
| chi2inv(p,df)
|
nu で指定されたパラメータを持つXでの対応する確率に対するカイ二乗累積密度関数の逆数を計算します。
=p=\frac 1{2^{\nu /2}\Gamma (\nu /2)}\int_0^{x_p}X^{\nu /2-1}e^{X/2}dX")
|
| finv(p,df1,df2)
|
パラメータdf1 とdf2 を持つp におけるF 累積密度関数を計算します。
")
=
& \frac{\nu _1^{\nu_1/2}\nu _2^{\nu _2/2}\Gamma ((\nu _1+\nu _2)/2)}{\Gamma (\nu _1/2)\Gamma (\nu _2/2)}\\ & \cdot \int_0^{f_p}F^{(\nu _1-2)/2}(\nu _1F+\nu _2)^{-(\nu _1+\nu _2)/2}dF\end{aligned}")
ここで、 ; ; 
|
| foldnorminv(p,mu,sigma)
|
分布パラメータmuとsigmaを持つ折りたたまれた正規分布の指定された下側確率pに関連する偏差xを計算します。
|
| gaminv(p,a,b)
|
パラメータaとb を持つpにおけるガンマ累積密度関数を計算します。
=\frac 1{\beta ^\alpha \Gamma (\alpha )}\int_0^{g_p}G^{\alpha -1}e^{-G/\beta }dG")
ここで  ; ;
|
| Landauinv(p,mu,sigma)
(2024b)
|
位置パラメータmuおよびスケールパラメータsigmaを使用して、pにおけるランダウ累積密度関数の逆関数を計算します。
|
| logninv(p,mu,sigma)
(2015 SR0)
|
パラメータmu と sigma の対数正規分布の下側確率pに関連づいた偏差xを計算します。
-\mu\right)^2}{2\sigma^2}}dt")
ここで、 
|
| norminv(p)
|
標準正規分布の与えられた下側確率pでの偏差xを計算します。

ここで 
|
| srangeinv(p,v,ir)
|
スチューデント範囲統計分布の下側確率での偏り xを計算します。
-\min (x_i)}{ \hat{\sigma _e} }")
|
| tinv(p,df)
|
自由度を持つスチューデントt分布の下側確率の偏りを計算します。
![P(T\leq t_p)=\frac{\Gamma ((\nu +1)/2)}{\sqrt{\pi \nu }\Gamma (\nu /2)}\int_{-\infty }^{t_p}[1+\frac{T^2}\nu ]^{-(\nu +1)/2}dT](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-08463b6d65b20a8e21302c2da6f15889.png "P(T\leq t_p)=\frac{\Gamma ((\nu +1)/2)}{\sqrt{\pi \nu }\Gamma (\nu /2)}\int_{-\infty }^{t_p}[1+\frac{T^2}\nu ]^{-(\nu +1)/2}dT") , , 
|
| wblinv(p,a,b)
|
パラメータ a と b を使って、与えられた確率に対する逆ワイブル累積分布関数を計算します。
![x_p=[aln(\frac 1{1-p}]^{(\frac 1b)}I_{[0,1]}(p)](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-ec6eae6ffd809a7050a0478ba2df12ef.png "x_p=[aln(\frac 1{1-p}]^{(\frac 1b)}I_{[0,1]}(p)")
|
データ生成関数
このカテゴリーの関数のうち、 rnd()/ran()およびgrnd()は、1つの値を返します。他の関数は範囲を返します。
| Note:乱数生成のOriginのメソッドのシードアルゴリズムは、バージョン2016で変更されました。詳細は、システム変数@ranを参照してください。
|
| 名前
|
説明
|
| Data(x1,x2,inc)
|
x1 と x2 の2つの値でデータセットを作ります。x1 から x2 の範囲で、増分は inc です。x1 = x2の場合、x1の値でのinc数を返します。incのデフォルト値は1です。サンプル:col(A) = data(0,100,5) は、列Aを0から100、増分5の値を入力します。
-
col(A) = data(10, 10, 5) A列の最初から5行目までに10が割り当てられます。
-
col(A) = data(1,100) 増分= 1で、1から100までの数字で列Aを埋めます。
|
| grnd()
|
関数grnd()は、平均=0と標準偏差=1を持つ、正規(ガウス)分布の乱数の標本値を返します。初期値と値のシーケンスは、各Originセッションで同じです。引数は必要ありません。一般に、この関数は、式 grnd()*sd+m を使用して、既知の平均値と標準偏差の正規分布からランダムな値を返すために使用されます。サンプル:
-
aa=grnd()*0.30855+0.45701 は 0.33882089669989を返します。
|
| normal(npts[,seed])
|
nptsの範囲を返します。値は、平均=0、標準偏差=1の正規(ガウス)分布で与えられる正規乱数です。seedが省かれている場合には、この関数が使われる度に異なるseedが使われます。平均値と標準偏差を指定して、正規分布のランダム値を列に入力するために使用できます: normal(npts)*sd+m。サンプル:
-
col(1) = normal(100)*2+5 列1に100ランダム値を平均=5およびSD=2で入力します。
|
| pattern(vd, onerepeat, seqrepeat) および pattern(x1,x2,inc,onerepeat,seqrepeat)
|
パターン化数値またはテキストデータを返します。pattern(vd, onerepeat, seqrepeat)は、文字列シリーズ vd と vd にあるそれぞれの要素を Onerepeat かつ、文字列全体を onerepeat 回繰り返します。pattern(x1,x2,inc,onerepeat,seqrepeat) は、増分incで増加するx1 から x2 の範囲でデータセットを生成します。データセットの個々の要素は、onerepeat回繰り返され、データセット全体はseqrepeat回繰り返されます。文字列シリーズの要素は、パイプ (|)、カンマ(,)、またはスペースや、 範囲変数によって分割されます。サンプル:
col(a)=pattern("Origin Lab", 2, 2); は、「Origin Origin Lab Lab Origin Origin Lab Lab」でA列を埋めます。col(b)=pattern(1,3,1,2,2); は"1 1 2 2 3 3 1 1 2 2 3 3".でB列を埋めます。
|
| Poisson(n, mean [,seed])
|
平均値 mean のポアソン分布を持つn個のランダムな整数を返します。 seed は任意で乱数生成のシードを提供します。サンプル:
-
col(1)=Poisson(100,5,1) 平均5のポアソン分布を持つ100ランダム値を列1に入力します。
|
| ran([seed]) および rnd([seed])
|
一様分布の標本から0から1の間の値を返します。オプションseedが正の場合、0を返します。seed ≤ 0 あるいは、引数がない場合は、乱数系列中の次の数を返します。
|
| uniform(npts [,seed]) および uniform(npts, vd)
|
nptsの範囲を返します。オプション seed は値、データ範囲、区切り文字列 ("|", "," またはスペース) 、文字列配列です。seed が値の場合、一様乱数を返します。seed がデータ範囲、文字列配列の場合、データ範囲や文字列から選ばれた値が返されます。seedが省かれている場合には、この関数が使われる度に異なるseedが使われます。この関数も、引数として、ベクトル vd を受け入れます。
|
ルックアップと参照関数
| 名前
|
説明
|
| Category(vd)$
(2020b)
|
カテゴリデータのベクトルvdを取り、すべてのカテゴリをワークシートの列に返します。カテゴリ順はソース列に従います。サンプル:
-
category([automobile]automobile!Make); // Set Values dialog form, "$" optional
-
range rA = [automobile]automobile!col(b); col(b) = category(rA)$; // LT script form, "$" needed
|
| Catindex(vd)
(2020b)
|
カテゴリデータのベクトルvdを取り、各要素のカテゴリインデックスをワークシート列に返します。サンプル:
|
| Catrows(vd[,option])
(2024b)
|
カテゴリデータのベクトルvdを取り、カテゴリごとのすべての行インデックスのパイプ区切りリストを返します。オプションの option で、各カテゴリのすべて/最初/最後のインデックスを返すかどうかを決定します。カテゴリ順はソース列に従います。サンプル:
-
catrows([automobile]automobile!B); // Set Values dialog form, "$" optional
-
range rA = [automobile]automobile!col(b); col(b) = catrows(rA)$; // LT script form, "$" needed
|
| Cattext(n,vd)$
(2020b)
|
カテゴリデータのベクトルvdを取り、n番目のカテゴリ値を返します。サンプル:
-
cattext(H,B); // Set Values dialog form, "$" optional
-
range rA = [automobile]automobile!col(b); col(b) = cattext(col(a),rA)$; // LT script form, "$" needed
|
| Findmasks(vd)
|
マスクされたデータを含む vd をとり、マスクされたポイントのインデックスからなるベクトルを返します。 サンプル:
-
dataset aa=findmasks(col(b)); col(d)=aa 列Dに、列Bのマスクされたデータの行インデックスを入力します。
|
| Firstpoint(vd)
|
ベクトル型 vd をとり、データセットvdの最初の値を返します。 サンプル:
-
aa = firstpoint(col(A)); 列Aの最初の値を取得し、変数aaに代入します。
|
| Idx(vBool)
|
単一のベクトルを含む条件式vBoolを評価し、条件を満たすすべてのレコードの行インデックスを含む整数のベクトルを返します。サンプル:
-
idx(A); true (1) 値のインデックスを返します。
-
idx(B>=20 && B<=50); Bの値が20~50のインデックスを返します。
-
idx(left(A,5)$ == "Chris"); Aの値の最初の5文字が"Chris"であるインデックスを返します。
|
| Index(d,vd[,n])
|
単調なデータのベクトル vd をとり、データポイントdの番号を返します。オプションn = 0 (デフォルト)はdの値と同じ、または近い値を見つけ、 n = 1 は ≤ d、n = 2 は ≥ dを探します。vd が狭義単調でなくテキストも含まない場合は、-2を返します。サンプル:
-
index(170,col(1)); 列1内の170に等しいか最も近い値のインデックスを返します。
|
| Lastpoint(vd)
|
ベクトル型 vd をとり、最大値を返し、データセットvdの最初の値を返します。 サンプル:
-
aa = lastpoint(col(A)); 列Aの最後の値を取得し、それを変数aaに代入します。
|
| List(val,vd)
|
ベクトル vd をとり、値val が最初のに出現したデータセットインデックス番号を返します。valがない場合、0を返します。サンプル:
-
list(3, col(A)) は、列Aを検索し、値3 が見つかった場所のインデックス番号を返します。
|
| lookup(str$,vs,vref[,option,Case])[$]
(2015 SR0)
|
ベクトルvs内で、文字列str$を検索し、同じインデックスのベクトルvref(数値または文字列)の値を返します。optionにより一致の精度を決めます。Case = 0(デフォルト)の場合、大文字小文字の区別をしません。サンプル:
-
string str1$ = Lookup("FSA", col(A), col(B))$; は、列Aで文字列 FSA を探し、文字列 FSA と同じインデックス番号を持つ列Bのセル内の値を str1$ に割り当てます。
|
| table(vd,vref,d[,option])[$]
(2015 SR0)
|
ベクトルvd内の値dを検索し、同じインデックス番号を持つvref内の値を返します。vrefに応じて数値か文字列を返します。パラメータoptionはパラメータdの検索を修正します。-1(デフォルト) = vd vs vrefで線形補間を実行し、補間された値を返す; 0 = ≤ d の直近の値を検索; 1 = ≥ d の直近の値を検索; 2 = 値に等しいまたは直近の値を検索
|
| unique(vs[, sort, occurrence, sort2])
(2018b)
|
ベクトル型 vs をとり、固有値を返します。パラメータsortは、返された固有値を並べ替えるかどうかを決定します。1(既定)= sort ascendingly; 0 =ソートなし; 2 =降順に並べ替えます。パラメーターoccurrenceは、重複した値を減らす方法を指定します。0 (デフォルト) = 最初の重複値を保持、1 = 最後の重複値を保持。sort2は、出現の処理方法を決定します: 0 (デフォルト) = 出現をソートしない、1 = 出現を昇順でソートします。2 =出現を降順にソートします。例:
-
StringArray sA; sA = unique(col(a)); // assign unique values in col(a) to stringArray sA, in ascending order
|
| ReportCell(sBook$,sSheet$,sTable$,sRowRef$,sColRef$)
(2021b)
|
指定されたブック名sBook、シート名sSheet、テーブル名sTable、およびセルの行と列の参照sRowRefとsColRefによるレポートシートテーブルセルへアクセスします。サンプル: Book1データでガウスフィット後、以下の式
-
ReportCell("Book1", "FitNL1", "Summary", "R1", "a_Value")は、パラメータ「A」のフィット値を返します。
Note:この関数は、セルの式でのみ使用できます。
|
| Xindex(x,vd[,option])
|
ベクトル vd (Yデータセット)をとり、x 値に近い vd のXデータセット内の値のインデックス番号を返します。どのインデックスを返すか、optionで指定します。0 (デフォルト) = 左から等しいか最も近い; 1 = 右から等しいか最も近い; 2 = 左右から等しいか最も近い。必要条件:(1) vd はY列である; (2) vd の名前は実際のYデータセットと一致; (3) Xデータセットは昇順。サンプル:
-
xindex(5,book1_g,1) (≥)5の右または右にあるx値の行インデックス番号を返します。
|
| Xvalue(n,vd)
|
ベクトルvd (Y またはZデータセット)をとり、行番号 n に対応するX値を返します。サンプル:
-
xvalue(20,book4_c) Book4の列Cの20行目にある列Cに関連付けられたx値を返します。
|
| Errof(vd)
|
ベクトル vd(データセット)をとり、vdの誤差値を含むデータセット(xEr/yEr)を返します。サンプル:
-
%a=errof(book1_b)はbook1_cを返します。
|
| hasx(vd)
|
データセットvd を取り、vdがアクティブレイヤのXデータセットに対してプロットされている場合、1を返します。そうでなければ、0を返します。サンプル:
-
aa=hasx(book1_b) アクティブなグラフレイヤに列Bのプロットが含まれている場合に1を返します。
|
| IsMasked(n,vd)
|
ベクトル型 vd をとり、n = 0 の場合はマスクされたポイント数を返します。n = データポイントのインデックス番号の場合、それがマスクされていれば1、されていなければ0を返します。サンプル:
-
ismasked(0,book1_b)はデータセットbook1_bに77マスクされたポイントがある場合 77を返します。
-
ismasked(8,book1_b) はn8がマスクされていない場合0を返し、マスクされている場合1を返します。
|
| Xof(vd)
|
Xデータセットに関連するYデータセットのベクトル名 vd をとり、Xデータセットの名前を含む文字列を返します。サンプル:
-
%a = xof(book1_b); book1_c = %a; // e.g. after substitution : book1_c = book1_a Yデータセットに関連付けられたXデータセットの名前を列Bに配置し、列CにX値を入力します。
|
データ操作関数
| 名前
|
説明
|
| asc(str$)
|
入力文字列をとり、文字列の最初の文字に対応するASCII コード(十進法)を返します。この関数はcode関数と処理をします。サンプル:
-
aa = asc($100); aa = は 36を返します。
|
| corr(vx,vy,k[, n])
|
2つのデータセット vx と vy、ラグサイズ k をとり、2つのデータセット間の相関を返します。オプション n は、ポイントの数です。ラグパラメータ k は、スカラーまたはベクトルです。kがベクトルの場合、関数はベクトルを返し、スカラーの場合はスカラーを返します。サンプル:
-
corr(col(1),col(2),data(1,10),50) は、1から10までのラグサイズを使用して、col(1)の最初の50ポイントとcol(2)の相互相関を返します。
|
| dropNA(vd[, text])
|
ベクトル型 vdをとり、欠損値とマスク値を削除します。オプションパラメータtextでテキストの扱いを指定します。 サンプル:
col(b)=dropNA(col(a))
|
| join(rA, rB, ...)
|
rA1:rA2, rB1:rB2,... として示される2つ以上の範囲を取り、それらを1つのデータセットに結合します。サンプル:
-
total(join(col(a)[1]:col(a)[32],col(b)[1]:col(b)[32])); 定義された範囲を結合し、合計を計算します。
-
=total(join(A1:A32,B1:B32)) //上記と同じですがセルまたは列の式のみの構文
|
| peaks(vd, width, minht)
|
ベクトルvdをとり、width とminhtを使用して検索されたピークのインデックスのデータセットを返します。width は、テストポイントの両側のポイント数です。minht はY軸の単位です。インデックスiで表されるピークは、(i-width)又は(i+width)のデータ値より大きいminhtとなります。サンプル:
-
peaks(col(B), 3, 0.1) ピークインデックスのデータセットを返します。
|
| rank(vd[, n])
|
データセットvdをとってソートし、ランク付けされたインデックスを返します。n = 0 (デフォルト)の場合、vdは昇順でソートされ、n = 1の場合降順でソートされます。vdに重複した値が存在する場合、重複した各値のランク付けされたインデックスの平均数を返します。サンプル:
-
col(C)=rank(col(B),1); col(B)のデータを取り、そのランク付けされたインデックスをcol(C)に出力する。
|
| reverse(vd)
|
ベクトル vd をとり順序を反転します。 サンプル:
col(B)=reverse(col(A))
|
| sort(vd)
|
データセットをとり、昇順でソートして返します。サンプル:
-
%a=sort(book4_c); book4_d=%a は、列Cをソートし、結果を列Dに入れます。
|
| treplace(vd,val1,val2[, cnd])
|
条件cndが合致すると、データセットを他の値と入れ替えます。データセット vd をとり、各値を cnd に対してval1 と比べ、比較が真の場合 val2 (または -val2) で置き換えます。偽の場合は値を残すか欠損値("--")で埋めます。
|
NAG 特殊関数
エアリー
ベッセル
| 名前
|
説明
|
| bessel_i0(x)
|
Bessel i0。第一種修正ベッセル関数の近似値 I0(x)を求めます。
|
| bessel_i0_scaled(x)
|
Bessel i0 scaled。式 ") の近似値を求めます。 の近似値を求めます。
|
| bessel_i1(x)
|
Bessel i1。第一種修正ベッセル関数 ") の近似値を求めます。 の近似値を求めます。
|
| bessel_k1_scaled(x)
|
Bessel i1 scaled。式 ") の近似値を求めます。 の近似値を求めます。
|
| bessel_i_nu(x,nu)
|
Bessel i nu。第一種修正ベッセル関数の近似値 I /4 (x) を求めます。 /4 (x) を求めます。
|
| bessel_i_nu_scaled(x,nu)
|
スケール済みBessel i nu。第一種修正ベッセル関数 ") の近似値を求めます。 の近似値を求めます。
|
| bessel_j0(x)
|
Bessel j0。第一種ベッセル関数 ") を計算します。 を計算します。
|
| bessel_j1(x)
|
Bessel j1。第一種ベッセル関数 ") の近似値を求めます。 の近似値を求めます。
|
| bessel_k0(x)
|
Bessel k0。第二種修正ベッセル関数,") の近似値を求めます。 の近似値を求めます。
|
| bessel_k0_scaled(x)
|
Bessel k0 scaled。式 ") の近似値を求めます。 の近似値を求めます。
|
| Bessel_k1(x)
|
Bessel k1。第二種修正ベッセル関数,") の近似値を求めます。 の近似値を求めます。
|
| bessel_k1_scaled(x)
|
Bessel k1 scaled。式 ") の近似値を求めます。 の近似値を求めます。
|
| bessel_k_nu(x,nu)
|
Bessel k nu。第二種修正ベッセル関数,") の近似値を求めます。 の近似値を求めます。
|
| bessel_k_nu_scaled(x,nu)
|
スケール済みBessel k nu。第二種修正ベッセル関数,") の近似値を求めます。 の近似値を求めます。
|
| bessel_y0(x)
|
Bessel y0。第二種ベッセル関数  ,x > 0を計算します。近似値はChebyshev拡張に基づいています。 ,x > 0を計算します。近似値はChebyshev拡張に基づいています。
|
| bessel_y1(x)
|
Bessel y1。第二種ベッセル関数  ,x > 0を計算します。近似値はChebyshev拡張に基づいています。 ,x > 0を計算します。近似値はChebyshev拡張に基づいています。
|
誤差
ガンマ
積分
ケルビン
その他
フィット関数
このカテゴリの複数のパラメータを持つ関数は、組込関数として、非線形フィットなどに使用されます。NLFitを開く(解析:フィット:非線形曲線フィット)と、数式、サンプル曲線、各パラメータ関数に関する詳細を確認できます。そして、関数選択ページから関数を選択します。
Originの非線形フィットから利用できる複数パラメータ関数の詳細については、 OriginLab ウェブサイトにあるPDFファイルをご覧下さい。このファイルでは、各複数パラメータ関数についての数学的な説明、サンプル曲線、パラメータについての解説、LabTalk関数のシンタックスが記載されています。
Origin Basic Functions
| 名前
|
説明
|
| Allometric1(x,a,b)
|
古典的なFreundlichモデル。相対成長の研究で使われます。

|
| Beta(x,y0,xc,A,w1,w2,w3)
|
クロマトグラフィと分光法で使われるBeta ピーク関数。
![\begin{aligned}y=&y_0+A\left[1+\left(\frac{w_2+w_3-2}{w_2-1}\right)\left(\frac{x-x_c}{w_1}\right)\right]^{w_2-1}\\
&\cdot\left[1-\left(\frac{w_2+w_3-2}{w_3-1}\right)\left(\frac{x-x_c}{w_1}\right)\right]^{w_3-1}\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-435026e27a6fde1c3d28aab6db0db1b4.png "\begin{aligned}y=&y_0+A\left[1+\left(\frac{w_2+w_3-2}{w_2-1}\right)\left(\frac{x-x_c}{w_1}\right)\right]^{w_2-1}\\
&\cdot\left[1-\left(\frac{w_2+w_3-2}{w_3-1}\right)\left(\frac{x-x_c}{w_1}\right)\right]^{w_3-1}\end{aligned}")
|
| Boltzmann(x, A1, A2, x0, dx)
|
Boltzmann関数 - シグモイド曲線を生成します。
/dx}}")
|
| dhyperbl(x,P1,P2,P3,P4,P5)
|
二重直角双曲線関数。

|
| ExpAssoc(x,y0,A1,t1,A2,t2)
|
2次の指数関連等式
 + A_2(1 - e^{-x/t_2})")
|
| ExpDec1(x,y0,A1,t1)
|
一定時間パラメータの1次指数減少関数

|
| ExpDec2(x,y0,A1,t1,A2,t2)
|
一定時間パラメータの2次指数減少関数

|
| ExpDec3(x,y0,A1,t1,A2,t2,A3,t3)
|
一定時間パラメータの3次指数減少関数

|
| ExpGrow1(x,y0,x0,A1,t1)
|
時間オフセット付き1次指数増加関数。x0は固定。
/t_1}")
|
| ExpGrow2(x, y0, x0, A1, t1, A2, t2)
|
時間オフセット付き2次指数増加関数。x0は固定。
/t_1} + A_2e^{(x-x_0)/t_2}")
|
| Gauss(x, y0, xc, w, A)
|
ガウス関数の面積バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 面積)
)}e^{-2(\frac{x-x_c}{w})^2}")
|
| GaussAmp(x,y0,xc,w,A)
|
ガウスピーク関数の振幅バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 振幅)
 ^2}{2w^2}}")
|
| Hyperbl(x, P1, P2)
|
双曲線関数、酵素反応速度論のMichaelis-Mentenモデル

|
| Logistic(x, A1, A2, x0, p)
|
薬理学/化学でのロジスティック用量応答。4PL または 4PLC とも呼ばれます。
^p}")
|
| LogNormal(x,y0,xc,w,A)
|
対数が正規分布するランダム変数の確率密度関数
![y=y_0+\frac A{\sqrt{2\pi }wx}e^{\frac{-\left[ \ln \frac x{x_c}\right] ^2}{2w^2}}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-3220dc36e6a1075cbff267293aa3febe.png "y=y_0+\frac A{\sqrt{2\pi }wx}e^{\frac{-\left[ \ln \frac x{x_c}\right] ^2}{2w^2}}")
|
| Lorentz(x, y0, xc, w, A)
|
ベル型でGaussian関数より幅の広いLorentzianピーク関数
(y0 = オフセット, xc = 中心, w = FWHM, A = 面積)
^2 + w^2}\right)")
|
| Poisson(x,y0,r)
|
Poisson確率密度関数。離散確率分布

|
| Pulse(x, y0, x0, A, t1, P, t2)
|
指数パルス関数(x >= x0 ? y : 0)
\\
&y=y_0+A\left( 1-e^{-\frac{x-x_0}{t_1}}\right) ^p e^{-\frac{x-x_0}{t_2}}~~(x\ge x_0)\end{aligned}")
|
| Rational0(x,a,b,c)
|
1次の分子と1次の分母を持つRational関数

|
| Sine(x,y0,xc,w,A)
|
特定の値の周囲で振動するSin波関数
")
|
| Voigt(x,y0,xc,A,wG,wL)
|
Gaussian関数とLorentzian関数のコンボリューション
(y0 = オフセット, xc = 中心, A =面積, wG = Gaussian FWHM, wL = Lorentzian FWHM)
 ^2+\left( \sqrt{4\ln 2}\frac{x-x_c}{W_G}-t\right) ^2}dt\end{aligned}")
|
Implicit
| 名前
|
説明
|
| Circle(x,y,xc,yc,r)
|
円中心と半径のパラメータの陰円関数
^2+(y-y_c)^2-r^2")
|
| Ellipse(x,y,xc,yc,a,b)
|
XY軸と一致する主軸副軸の陰楕円関数
^2 + \left(\frac{y-y_c}{b}\right)^2 - 1")
|
| ModDiode(V,I,T,Is,Rs,n,Rsh)
|
暗黙的に修正されたダイオード方程式
}{nkT}}-1 \right)+\frac{V-I\cdot R_s}{R_{sh}}-I")
|
| PlaneMod(x,y,z,theta,phi,d)
|
正規方向で定義された修正陰平面関数
\cos(\phi)x + \sin(\theta)\sin(\phi)y + \cos(\theta)z + d")
|
| SolarCellIV(V,I,T,Is,Rs,n,Rsh,IL)
|
太陽電池のI-V曲線
}{nkT}}-1 \right)+\frac{V+I\cdot R_s}{R_{sh}}-I_L")
|
Exponential
| 名前
|
説明
|
| Asymptotic1(x,a,b,c)
|
Asymptotic回帰モデル- 1次パラメータ

|
| BoxLucas1(x,a,b)
|
0オフセットの1次結合関数に等しいBox Lucasモデル
")
|
| BoxLucas1Mod(x,a,b)
|
Box Lucasモデルのパラメータ化
")
|
| BoxLucas2(x,a1,a2)
|
2次のBox Lucasモデル
")
|
| Chapman(x,a,b,c)
|
累積成長曲線を説明するChapman-Richards関数
^c")
|
| Exp1p1(x,A)
|
1つのパラメータの指数関数

|
| Exp1p2(x,A)
|
1つのパラメータの指数関数

|
| Exp1p2Md(x,B)
|
1つのパラメータの指数関数

|
| Exp1P3(x,A)
|
1つのパラメータの指数関数

|
| Exp1P3Md(x,B)
|
1つのパラメータの指数関数
B^x")
|
| Exp1P4(x,A),
|
1つのパラメータの漸近指数関数

|
| Exp1P4Md(x,B)
|
1つのパラメータの漸近指数関数の変形

|
| Exp2P(x,a,b)
|
2つのパラメータの指数関数

|
| Exp2PMod1(x,a,b),
|
2つのパラメータの指数関数

|
| Exp2PMod2(x,a,b),
|
2つのパラメータの指数関数

|
| Exp3P1(x,a,b,c),
|
指数関数の逆オフセット

|
| Exp3P1Md(x,a,b,c),
|
指数関数の逆オフセットの別の形

|
| Exp3P2(x,a,b,c),
|
べき指数が2次の多項式の指数関数

|
| ExpAssoc(x,y0,A1,t1,A2,t2)
|
2次の指数関連等式
|
| ExpAssoc1(x,TD,Yb,A,Tau)
(2017 SR0)
|
1次の指数関連等式
}{Tau}}\right)")
|
| ExpAssoc2(x,TD1,TD2,Yb,A1,A2,Tau1,Tau2)
(2017 SR0)
|
二相指数関連方程式
}{Tau_{1}}} \right ) \quad \quad \quad \quad \quad \quad\quad\quad \quad \quad x<TD_{2}\\
Yb+A_{1}\left ( 1-e^{-\frac {(x-TD_{1})}{Tau_{1}}}\right )+A_{2}\left ( 1-e^{-\frac {(x-TD_{2})}{Tau_{2}}}\right ) x\geq TD_{2}
\end{matrix}\right.")
|
| ExpAssocDelay1(x,TD,Yb,A,Tau)
(2017 SR0)
|
指数関数が始まる前のプラトーを用いた一相指数関数方程式
}{Tau}}\right ) \quad x\geq TD
\end{matrix}\right.")
|
| ExpAssocDelay2(x,TD1,TD2,Yb,A1,A2,Tau1,Tau2)
(2017 SR0)
|
指数関数が始まる前のプラトーを用いた二相指数関数方程式
}{Tau_{1}}} \right ) \quad \quad \quad \quad \quad \quad\quad TD_{1}\leq x<TD_{2}\\
Yb+A_{1}\left ( 1-e^{-\frac {(x-TD_{1})}{Tau_{1}}}\right )+A_{2}\left ( 1-e^{-\frac {(x-TD_{2})}{Tau_{2}}}\right ) x\geq TD_{2}
\end{matrix}\right.")
|
| Exponential(x,y0,A,R0)
|
一定率パラメータの指数増加関数

|
| ExpDec1(x,y0,A1,t1)
|
一定時間パラメータの1次指数減少関数
|
| ExpDec2(x,y0,A1,t1,A2,t2)
|
一定時間パラメータの2次指数減少関数
|
| ExpDec3(x,y0,A1,t1,A2,t2,A3,t3)
|
一定時間パラメータの3次指数減少関数
|
| ExpDecay1(x,y0,x0,A1,t1)
|
時間オフセット付き1次指数減少 。x0は修正。
/t_1}")
|
| ExpDecay2(x, y0, x0, A1, t1, A2, t2)
|
時間オフセット付き2次指数減少 。x0は修正。
/t_1} + A_2e^{-(x-x_0)/t_2}")
|
| ExpDecay3(x,y0,x0,A1,t1,A2,t2,A3,t3)
|
時間オフセット付き3次指数減少 。x0は修正。
/t_1}+A_2e^{-(x-x_0)/t_2}+\\
&A_3e^{-(x-x_0)/t_3}\end{aligned}")
|
| ExpGro1(x,y0,A1,t1)
|
一定時間パラメータの1次指数増加関数

|
| ExpGro2(x,y0,A1,t1,A2,t2)
|
一定時間パラメータの2次指数増加関数

|
| ExpGro3(x,y0,A1,t1,A2,t2,A3,t3)
|
一定時間パラメータの3次指数減少関数

|
| ExpGrow1(x,y0,x0,A1,t1)
|
時間オフセット付き1次指数増加関数。x0は固定。
|
| ExpGrow2(x, y0, x0, A1, t1, A2, t2)
|
時間オフセット付き2次指数増加関数。x0は固定。
|
| ExpGrow3Dec2(x,y0,xc,Ag1,tg1,Ag2,tg2,Ag3,tg3,Ad1,td1,Ad2,td2)
(2015 SR0)
|
3つの成長と2つの減衰を伴う指数関数。
\qquad\qquad\qquad\qquad\qquad\\+A_{g2}\left ( e^{-x_{c}/t_{g2}}-e^{-x/t_{g2}} \right )\qquad \qquad \qquad \qquad \qquad \\+A_{g3}\left ( e^{-x_{c}/t_{g3}}-e^{-x/t_{g3}} \right )\qquad \qquad \qquad \quad x\leq x_{c}\\
y_{0}+A_{d1}e^{-\left ( x-x_{c} \right )/t_{d1}}+A_{d2}e^{-\left ( x-x_{c} \right )/t_{d2}}\qquad x>x_{c}
\end{matrix}\right.")
|
| ExpGrowDec(x,y0,xc,Ag,tg,Ad,td)
(2015 SR0)
|
1つの成長と1つの減衰を伴う指数関数。
 \quad x\leq x_{c}\\
y_{0}+A_{d}e^{-\left ( x-x_{c} \right )/t_{d}}\qquad \qquad\qquad \quad x>x_{c}
\end{matrix}\right.")
|
| ExpLinear(x,p1,p2,p3,p4)
|
指数と線形の組合せ

|
| Langevin(x,y0,xc,C)
|
3つのパラメータの常磁性で使用するLangevin 関数
 -\frac 1{x-x_c}\right) \\
&\coth z=\frac{e^z+e^{-z}}{e^z-e^{-z}}\end{aligned}")
|
| LangevinMod(x,y0,xc,C,s)
(2015 SR0)
|
スケール修正 Langevin関数
 -\frac {s}{x-x_c}\right)")

|
| PIPlatt(x,Pm,alpha)
(2017 SR0)
|
Plattによる光合成−光曲線モデル
")
|
| PIPlatt2(x,Ps,alpha,beta)
(2017 SR0)
|
Plattによる光阻害のある光合成−光曲線モデル
e^{-\frac {beta\cdot x}{P_{s}}}")
|
| PIWebb(x,Pm,alpha)
(2017 SR0)
|
Webbによる光合成−光曲線モデル
")
|
| MnMolecular(x,A,xc,k),
|
単分子の成長関数
 }\right)")
|
| MnMolecular1(x,A1,A2,k)
|
単分子の成長関数の別の形

|
| Shah(x,a,b,c,r)
|
線形関数を統合した指数減少関数

|
| Stirling(x,a,b,k)
|
パラメータとしてゼロにおける傾きの指数増加関数
")
|
| YldFert(x,a,b,r)
|
農業での収穫肥料モデル、心理学での学習曲線

|
| YldFert1(x,a,b,k)
|
農業での収穫肥料モデル、心理学での学習曲線

|
Growth/Sigmoidal
| 名前
|
説明
|
| BiDoseResp(x,A1,A2,LOGx01,LOGx02,h1,h2,p)
|
二相容量応答関数
![\begin{aligned}y=&A_1+(A_2-A_1)\bigg[\frac{p}{1+10^{(LOGx01-x)h1}}+\\
&\frac{1-p}{1+10^{(LOGx02-x)h2}}\bigg]\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-5a931673f336d3539f282df4fd1d9752.png "\begin{aligned}y=&A_1+(A_2-A_1)\bigg[\frac{p}{1+10^{(LOGx01-x)h1}}+\\
&\frac{1-p}{1+10^{(LOGx02-x)h2}}\bigg]\end{aligned}")
|
| BiHill(x,Pm,Ka,Ki,Ha,Hi)
(2015 SR0)
|
二相ヒル関数
![y=\frac{P_{m}}{[1+(\frac{K_{a}}{x})^{H_{a}}][1+(\frac{x}{K_{i}})^{H_{i}}]}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-ce7a5e8d7f9f7b024ec8fa9326a65009.png "y=\frac{P_{m}}{[1+(\frac{K_{a}}{x})^{H_{a}}][1+(\frac{x}{K_{i}})^{H_{i}}]}")
|
| BoltzIV(x,vhalf,dx,gmax,vrev)
|
IVデータに対する変換済みボルツマン関数
\cdot gmax }{1+e^{(x-vhalf)/dx}}")
|
| Boltzmann(x, A1, A2, x0, dx)
|
Boltzmann関数 - シグモイド曲線を生成します。
/(1 + e^{(x-x0)/dx})")
|
| DoseResp(x,A1,A2,LOGx0,p)
|
パラメータ'p'によって与えられた変数Hill傾きの容量応答曲線
 p}}")
|
| DoubleBoltzmann(x,y0,A,frac,x01,x02,k1,k2)
|
二重Boltzmann関数。2つのBoltzmann関数の合計
![y=y_0+A\left[\frac{p}{1+e^{\frac{x-x_{01}}{k_1}}}+\frac{1-p}{1+e^{\frac{x-x_{02}}{k_2}}}\right]](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-649e5dcc558a3cbe663ecabcca96fc0e.png "y=y_0+A\left[\frac{p}{1+e^{\frac{x-x_{01}}{k_1}}}+\frac{1-p}{1+e^{\frac{x-x_{02}}{k_2}}}\right]")
|
| Hill(x,Vmax,k,n)
|
配位子濃度と結合部位の最大数を決定するHill関数

|
| Hill1(x,START,END,k,n)
|
オフセット付きの修正Hill関数
|
| Logistic(x, A1, A2, x0, p)
|
薬理学/化学でのロジスティック用量応答。4PL または 4PLC とも呼ばれます。
|
| Logistic5(x,Amin,Amax,x0,h,s)
|
5つのパラメータを持つ、ロジスティック関数。5PL または 5PLC とも呼ばれます。
^{-h}\right)^s}")
|
| MichaelisMenten(x,Vmax,Km)
|
酵素動力学の基本モデル。単一基質 Michaelis-Menten関数。

|
| SGompertz(x,a,xc,k)
|
動物の成長や人口増加の研究でのGompertz成長モデル
)}")
|
| Slogistic1(x,a,xc,k)
|
タイプ1のシグモイドロジスティック関数
 }}")
|
| SLogistic2(x,y0,a,Wmax)
|
タイプ2のシグモイドロジスティック関数

|
| SLogistic3(x,a,b,k)
|
タイプ3のシグモイドロジスティック関数

|
| SRichards1(x,a,xc,d,k)
|
タイプ1のシグモイドリチャード関数
![y=\left[ a^{1-d}-e^{-k\left( x-x_c\right) }\right] ^{1/\left( 1-d\right) },d<1](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-2cef129b1d404b1a78cbef3fef041d59.png "y=\left[ a^{1-d}-e^{-k\left( x-x_c\right) }\right] ^{1/\left( 1-d\right) },d<1")
![y=\left[ a^{1-d}+e^{-k\left( x-x_c\right) }\right] ^{1/\left( 1-d\right) },d>1](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-e2d761428ae5521d47b9f95878bad13c.png "y=\left[ a^{1-d}+e^{-k\left( x-x_c\right) }\right] ^{1/\left( 1-d\right) },d>1")
|
| SRichards2(x,a,xc,d,k)
|
タイプ2のシグモイドリチャード関数
![y=a\left[ 1+\left( d-1\right) e^{-k\left( x-x_c\right) }\right] ^{1/\left( 1-d\right) },d\neq 1](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-e5c7adcfd74d6710ffd6a0ca10d00c76.png "y=a\left[ 1+\left( d-1\right) e^{-k\left( x-x_c\right) }\right] ^{1/\left( 1-d\right) },d\neq 1")
|
| SWeibull1(x,A,xc,d,k)
|
タイプ1のシグモイドワイブル関数
 \right) ^d})")
|
| SWeibull2(x,a,b,d,k)
|
タイプ2のシグモイドワイブル関数
 e^{-\left( kx\right) ^d}")
|
Hyperbola
| 名前
|
説明
|
| Dhyperbl(x,P1,P2,P3,P4,P5)
|
二重直角双曲線関数。
|
| Hyperbl(x, P1, P2)
|
双曲線関数、酵素反応速度論のMichaelis-Mentenモデル
|
| HyperbolaGen(x,a,b,c,d)
|
一般化双曲線関数
 ^{1/d}}")
|
| HyperbolaMod(x,T1,T2)
|
修正双曲線関数

|
| RectHyperbola(x,a,b)
|
直角双曲線関数。

|
Logarithm
| 名前
|
説明
|
| Bradley(x,a,b)
|
二重対数相互関数
)")
|
| Log2P1(x,a,b),
|
2つのパラメータの対数関数
")
|
| Log2P2(x,a,b)
|
対数変換関数
")
|
| Log3P1(x,a,b,c)
|
線形対数変換関数
")
|
| Logarithm(x,A)
|
1つのパラメータの対数関数
")
|
ピーク関数
| 名前
|
説明
|
| Asym2Sig(x,y0,xc,A,w1,w2,w3)
|
非対称の2重シグモイド
")
|
| Beta(x,y0,xc,A,w1,w2,w3)
|
クロマトグラフィと分光法で使われるBeta ピーク関数。
![\begin{aligned}y=&y_0+A\left[1+\left(\frac{w_2+w_3-2}{w_2-1}\right)\left(\frac{x-x_c}{w_1}\right)\right]^{w_2-1}\\&\cdot\left[1-\left(\frac{w_2+w_3-2}{w_3-1}\right)\left(\frac{x-x_c}{w_1}\right)\right]^{w_3-1}\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-076b4d5daaea23eccbea1ff441b581bc.png "\begin{aligned}y=&y_0+A\left[1+\left(\frac{w_2+w_3-2}{w_2-1}\right)\left(\frac{x-x_c}{w_1}\right)\right]^{w_2-1}\\&\cdot\left[1-\left(\frac{w_2+w_3-2}{w_3-1}\right)\left(\frac{x-x_c}{w_1}\right)\right]^{w_3-1}\end{aligned}")
|
| Bigaussian(x,y0,xc,H,w1,w2)
|
非対称ピークのフィットに使用する二重Gaussianピーク関数
^2}~~~~~~(x < x_c ) \,\\
y&=y_0+He^{-0.5\left(\frac{x-x_c}{w_2}\right)^2}~~~~~~(x \geq x_c)\end{aligned}")
|
| CCE(x,y0,xc1,A,w,k2,xc2,B,k3,xc3)
|
クロマトグラフィで使われるChesler-Cramピーク関数
![\begin{aligned}y=&y_0+A\bigg[e^{-\frac{\left(x-x_{c1}\right)^2}{2w}}+B(1-0.5(1-\tanh (k_2(x-\\
&x_{c2}))))e^{-0.5k_3(|x-x_{c3}|+(x-x_{c3}))}\bigg]\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-8ba1f583218740b063ba686def196277.png "\begin{aligned}y=&y_0+A\bigg[e^{-\frac{\left(x-x_{c1}\right)^2}{2w}}+B(1-0.5(1-\tanh (k_2(x-\\
&x_{c2}))))e^{-0.5k_3(|x-x_{c3}|+(x-x_{c3}))}\bigg]\end{aligned}")
|
| ECS(x,y0,xc,A,w,a3,a4)
|
クロマトグラフィで使われるEdgeworth-Cramerピーク関数
+\frac{a_4}{4!}(z^4-\\
&6z^3+3)+\frac{10a_3^2}{6!}\left(z^6-15z^4+45z^2-15\right)\bigg)\\
z=&\frac{x-x_c}w\end{aligned}")
|
| Extreme(x,y0,xc,w,A)
|
特例のExtreme関数。Gumbel確率密度関数

|
| Gauss(x, y0, xc, w, A)
|
ガウス関数の面積バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 面積)
}e^{-2\left(\frac{x-x_c}{w}\right)^2}")
|
| GaussAmp(x,y0,xc,w,A)
|
ガウスピーク関数の振幅バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 振幅)
|
| Gaussian(x,y0,xc,A,w)
|
ガウス関数のFWHMバージョン
(y0 = ベースライン, xc = 中心, A = 面積, w = FWHM)
(x-x_c)^2}{w^2}}}{w \sqrt{\frac{\pi}{4ln(2)}}}")
|
| GaussMod(x,y0,A,xc,w,t0)
|
クロマトグラフィで使用される指数修正ガウス(EMG)ピーク関数
=y_0+\frac A{t_0}e^{\frac 12\left(\frac w{t_0}\right)^2-\frac{x-x_c}{t_0}}\int_{-\infty }^z\frac 1{\sqrt{2\pi }}e^{-\frac{y^2}2}dy\\
&z=\frac{x-x_c}w-\frac w{t_0} \end{aligned}")
|
| GCAS(x,y0,xc,A,w,a3,a4)
|
クロマトグラフィで使われるGram-Charlierピーク関数
 =y_0+\frac A{w\sqrt{2\pi }}e^{\frac{-z^2}2}\left( 1+\sum_{i=3}^4\frac{a_i}{i!}H_i\left( z\right) \right)\\
&z=\frac{x-x_c}w, H_3=z^3-3z, H_4=z^4-6z^2+3\end{aligned}")
|
| Giddings(x,y0,xc,w,A)
|
クロマトグラフィで使われるGiddingsrピーク関数
 e^{\frac{-x-x_c}w}")
|
| InvsPoly(x,y0,xc,w,A,A1,A2,A3)
|
中心の逆多項式ピーク関数
 ^2+A_2\left( 2\frac{x-x_c}w\right) ^4+A_3\left( 2\frac{x-x_c}w\right) ^6}\end{aligned}")
|
| Laplace(x,y0,a,b)
|
ラプラス確率密度関数

|
| Logistpk(x,y0,xc,w,A)
|
ロジスティックピーク関数。Hubbert関数とも呼ばれる。
 ^2}")
|
| LogNormal(x,y0,xc,w,A)
|
対数が正規分布するランダム変数の確率密度関数
![y=y_0+\frac A{\sqrt{2\pi }wx}e^{\frac{-\left[ \ln \frac x{xc}\right] ^2}{2w^2}}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-e98dcb616116ac2349df7544a55b124f.png "y=y_0+\frac A{\sqrt{2\pi }wx}e^{\frac{-\left[ \ln \frac x{xc}\right] ^2}{2w^2}}")
|
| Lorentz(x, y0, xc, w, A)
|
ベル型でGaussian関数より幅の広いLorentzianピーク関数
(y0 = オフセット, xc = 中心, w = FWHM, A = 面積)
^2 + w^2}\right)")
|
| PearsonIV(x,y0,A,m,v,alpha,lam)
|
負の判別子のためのピアソンのタイプIV分布。偏りのある分布に適合しやすい。
![\begin{aligned}&y=y_0+Ak\left[1+\left(\frac{x-\lambda\!}{\alpha\!}\right)\right]^{-m}e^{-v\tan^{-1}\left(\frac{x-\lambda\!}{\alpha\!}\right) } \\
&k=\frac{2^{2m-2}|\Gamma\!\left(m+iv/2\right)|^2}{\pi\!\alpha\!\Gamma\!\left(2m-1\right)}, m>\frac{1}{2}\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-2578f3f3d1060040453114eb42fee3a2.png "\begin{aligned}&y=y_0+Ak\left[1+\left(\frac{x-\lambda\!}{\alpha\!}\right)\right]^{-m}e^{-v\tan^{-1}\left(\frac{x-\lambda\!}{\alpha\!}\right) } \\
&k=\frac{2^{2m-2}|\Gamma\!\left(m+iv/2\right)|^2}{\pi\!\alpha\!\Gamma\!\left(2m-1\right)}, m>\frac{1}{2}\end{aligned}")
|
| PearsonVII(x,y0,xc,A,w,m)
|
ピアソンのタイプVIIピーク関数、べき乗されたローレンツ関数。
![\begin{aligned}&y=y_0+A\frac{2\Gamma (\mu)\sqrt{2^{\frac{1}{\mu}}-1}}{\sqrt{\pi }\Gamma \left( \mu-\frac 12\right) w}\bigg[ 1+4\frac{2^{\frac{1}{\mu}}-1}{w^2}\left( x-x_c\right) ^2\bigg] ^{-\mu}\\
&m=\mu\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-3dfdbeab0848b14621c0b803f539eb3b.png "\begin{aligned}&y=y_0+A\frac{2\Gamma (\mu)\sqrt{2^{\frac{1}{\mu}}-1}}{\sqrt{\pi }\Gamma \left( \mu-\frac 12\right) w}\bigg[ 1+4\frac{2^{\frac{1}{\mu}}-1}{w^2}\left( x-x_c\right) ^2\bigg] ^{-\mu}\\
&m=\mu\end{aligned}")
|
| PsdVoigt1(x,y0,xc,A,w,mu)
|
擬フォークト(Pseudo-Voigt)関数。Gaussian関数とLorentzian関数の線形混合
(y0 = オフセット, xc = 中心, A = 面積, w = FWHM, mu = プロファイル形要因)
![\begin{aligned}y=&y_0+A\bigg[ m_u\frac 2\pi \frac w{4\left( x-x_c\right) ^2+w^2}\\
&+\left( 1-m_u\right) \frac{\sqrt{4\ln 2}}{\sqrt{\pi}w}e^{-\frac{4\ln 2}{w^2}\left( x-x_c\right) ^2}\bigg]\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-a2bbe7b2678afc56a46e94e4092a69a5.png "\begin{aligned}y=&y_0+A\bigg[ m_u\frac 2\pi \frac w{4\left( x-x_c\right) ^2+w^2}\\
&+\left( 1-m_u\right) \frac{\sqrt{4\ln 2}}{\sqrt{\pi}w}e^{-\frac{4\ln 2}{w^2}\left( x-x_c\right) ^2}\bigg]\end{aligned}")
|
| PsdVoigt2(x,y0,xc,A,wG,wL,mu)
|
擬フォークト(Pseudo-Voigt)関数。異なるFWHMのGaussian関数とLorentzian関数の線形混合
(y0 = オフセット, xc = 中心, A =面積, wG=Gaussian FWHM, wL=Lorentzian FWHM, mu = プロファイル形要因)
![\begin{aligned}y=&y_0+A\bigg[ m_u\frac 2\pi \frac{w_L}{4\left( x-x_c\right) ^2+w_L^2}+\\
&\left( 1-m_u\right) \frac{\sqrt{4\ln2}}{\sqrt{\pi}w_G}e^{-\frac{4\ln 2}{w_G^2}\left( x-x_c\right) ^2}\bigg] \end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-71ad34b7a8ff4400fafbd7187d8bc5ff.png "\begin{aligned}y=&y_0+A\bigg[ m_u\frac 2\pi \frac{w_L}{4\left( x-x_c\right) ^2+w_L^2}+\\
&\left( 1-m_u\right) \frac{\sqrt{4\ln2}}{\sqrt{\pi}w_G}e^{-\frac{4\ln 2}{w_G^2}\left( x-x_c\right) ^2}\bigg] \end{aligned}")
|
| Voigt(x,y0,xc,A,wG,wL)
|
Gaussian関数(wG は FWHM) と Lorentzian 関数のコンボリューション
 ^2+\left( \sqrt{4\ln 2}\frac{x-x_c}{W_G}-t\right) ^2}dt\end{aligned}")
|
| Weibull3(x,y0,xc,A,w1,w2)
|
ワイブルピーク関数の振幅バージョン
![\begin{aligned}S&=\frac{x-x_c}{w_1}+\left( \frac{w_2-1}{w_2}\right) ^{\frac 1{w_2}}\\
y&=y_0+A\left( \frac{w_2-1}{w_2}\right) ^{\frac{1-w_2}{w_2}}\left[ S\right] ^{w_2-1}e^{-\left[ S\right] ^{w_2}+\left( \frac{w_2-1}{w_2}\right) }\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-508a00fe65b3a935b87f1c9096d0656a.png "\begin{aligned}S&=\frac{x-x_c}{w_1}+\left( \frac{w_2-1}{w_2}\right) ^{\frac 1{w_2}}\\
y&=y_0+A\left( \frac{w_2-1}{w_2}\right) ^{\frac{1-w_2}{w_2}}\left[ S\right] ^{w_2-1}e^{-\left[ S\right] ^{w_2}+\left( \frac{w_2-1}{w_2}\right) }\end{aligned}")
|
Piecewise
| 名前
|
説明
|
| PWL2(x,a1,k1,xi,k2)
|
2つの区分のPiecewise線形関数
\\
&y=y_i+k_2\left(x-x_i\right)~~~~~\left(x\ge x_i\right)\\
&y_i=a_1+k_1x_i \end{aligned}")
|
| PWL3(x,a1,k1,xi1,k2,xi2,k3)
|
3つの区分のPiecewise線形関数
\\
&y=y_{i_1}+k_2\left(x-x_{i_1}\right)~~~~~(x_{i_1}\le x<x_{i_2})\\
&y=y_{i_2}+k_3\left(x-x_{i_2}\right)~~~~~(x\ge x_{i_2})\\
&y_{i_1}=a_1+k_1x_{i_1},~ y_{i_2}=y_{i_1}+k_2\left(x_{i_2}-x_{i_1}\right) \end{aligned}")
|
Polynomial
| 名前
|
説明
|
| Constant(x,y0)
|
定数の線形関数

|
| Cubic(x,A,B,C,D)
|
3次の多項式

|
| Line(x,A,B)
|
傾きと切片を持つ線形関数

|
| LineMod(x,a,b)
|
X切片と傾きを持つ線形関数
")
|
| Parabola(x,A,B,C)
|
2次の多項式

|
| Poly(x, a0, a1, a2, a3, a4, a5, a6, a7, a8, a9)
|
9次の多項式

|
| Poly4(x,A0,A1,A2,A3,A4)
|
4次多項式関数

|
| Poly5(x,A0,A1,A2,A3,A4,A5)
|
5次多項式関数

|
Power
| 名前
|
説明
|
| Allometric1(x,a,b)
|
古典的なFreundlichモデル。相対成長の研究で使われます。
|
| Allometric2(x,a,b,c)
|
古典的なFreundlichモデル。

|
| Belehradek(x,a,b,c)
|
Xがシフトしたべき関数
^c")
|
| BlNeld(x,a,b,c,f)
|
収量密度モデルのBleasdale-Nelder関数
^{-1/c}")
|
| BlNeldSmp(x,a,b,c)
|
単純化Bleasdale-Nelder モデル
^{-1/c}")
|
| FarazdaghiHarris(x,a,b,c)
|
収量密度研究で使われるFarazdaghi-Harrisモデル
|
| FreundlichEXT(x,a,b,c)
|
拡張Freundlich 吸着等温式

|
| Gunary(x,a,b,c)
|
Gunary 吸着等温式

|
| LangmuirEXT1(x,a,b,c),
|
拡張Langmuir吸着等温式

|
| LangmuirEXT2(x,a,b,c)
|
拡張Langmuir吸着等温式の変形

|
| Pareto(x,A)
|
1つのパラメータのPareto累積密度関数。冪乗則確率分布

|
| Pow2P1(x,a,b),
|
スケールされたPareto関数
")
|
| Pow2P2(x,a,b),
|
2つのパラメータのpower関数
 ^b")
|
| Pow2P3(x,a,b)
|
Pareto変換関数
 ^b}")
|
| Power(x,A)
|
1つのパラメータのpower関数

|
| Power0(x,y0,xc,A,P)
|
オフセット付きの対称Power関数

|
| Power1(x,xc,A,P)
|
対称Power関数

|
| Power2(x,xc,A,pl,pu)
|
非対称Power関数

|
Rational
| 名前
|
説明
|
| BET(x,a,b)
|
Brunauer-Emmett-Teller (BET) 吸着式
x-(b-1)x^2}")
|
| BETMod(x,a,b)
|
修正BETモデル
x^2}")
|
| Holliday(x,a,b,c)
|
Holliday モデル - 農業で使われる収穫密度モデル
 ^{-1}")
|
| Holliday1(x,a,b,c)
|
拡張Hollidayモデル

|
| Nelder(x,a,b0,b1,b2)
|
Nelder モデル - 農業で使われる収穫-肥料モデル
+b_2\left( x+a\right) ^2}")
|
| Rational0(x,a,b,c)
|
1次の分子と1次の分母を持つRational関数
|
| Rational1(x,a,b,c)
|
一定係数で標準化した分子のRational0関数の別の形

|
| Rational2(x,a,b,c)
|
xの係数で標準化した分母のRational0関数の別の形

|
| Rational3(x,a,b,c)
|
x係数で標準化した分子のRational0関数の別の形

|
| Rational4(x,a,b,c)
|
定数とrational関数の合計付きRational0関数の別の形

|
| Rational5(x,a,b,c,d)
|
1次の分子と2次の分母を持つRational関数

|
| Reciprocal(x,a,b)
|
2つのパラメータの線形逆数関数

|
| Reciprocal0(x,A)
|
1つのパラメータ(傾き)の線形逆数関数

|
| Reciprocal1(x,A)
|
1つのパラメータ(切片)の線形逆数関数

|
| ReciprocalMod(x,a,b)
|
一定係数で標準化した分母のReciprocal関数の別の形

|
Waveform
| 名前
|
説明
|
| SawtoothWave(x,x0,y0,A,T)
|
のこぎり波。非対称な三角形の波で構成される周期関数。
,\\
&x_0+nT\le x < x_0+\left(n+1\right)T,\ n\in Z\end{aligned}")
|
| Sine(x,y0,xc,w,A)
|
特定の値の周囲で振動するSin波関数
|
| SineDamp(x,y0,xc,w,t0,A)
|
正弦波収束関数。時間経過とともに振幅が減少する正弦波関数
 \\
&A>0,~ t_0>0,~ w>0\end{aligned}")
|
| SineSqr(x,y0,xc,w,A)
|
Sin二乗関数
")
|
| SquareWave(x,a,b,x0,T)
|
2つのレベルで周期的に変化する矩形波関数
T,\ n\in Z\\
b,\ \ x_0+\left(n+\frac{1}{2} \right )T <x<x_0+\left(n+1 \right )T,\ n\in Z
\end{cases}")
|
| SquareWaveMod(x, a, b, x0, duty, T)
(2016 SR0)
|
2つのレベルで周期的に変化する矩形波関数
T, \ n\in Z, 0<duty<1\\ b,\ \ x_0+\left(n+duty \right )T <x<x_0+\left(n+1 \right )T,\ n\in Z, 0<duty<1 \end{cases}")
|
| Step(x,A,B,x1)
|
2つの区分のPiecewise 定数関数

|
Surface Fitting
| 名前
|
説明
|
| Chebyshev2D(x,y,z0,A1,A2,B1,B2,C1)
|
Chebyshev系列の多項式
 +B_1T_1\left( y\right) +A_2T_2\left( x\right) +\\
&CT_1\left( x\right) T_1\left( y\right) +B_2T2\left( y\right)~~~\end{aligned}")
 =\cos \left( na\cos \left( x\right) \right) \\
&T_n\left( y\right) =\cos \left( na\cos \left( y\right) \right) \\
&-1\leq x\leq 1, ~-1\leq y\leq 1\end{aligned}")
|
| Cosine(x,y,z0,A1,A2,B1,B2,C1)
|
Cos系列の多項式
 +B_1\cos \left( y\right) +A_2\cos \left( 2x\right) +\\
&C_1\cos \left( x\right) \cos \left( y\right)+B_2\cos \left( 2y\right) \\
0\leq& x\leq \pi, ~~0\leq y\leq \pi\end{aligned}")
|
| DoseResp2D(x,y,z0,B,C,D,E,F)
|
非線形ロジスティック用量応答(Dose Response)関数
![z=z_0+\frac B{\left[ 1+\left( \frac xC\right) ^{-D}\right] \left[ 1+\left( \frac yE\right) ^{-F}\right] }](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-f62653f29cbc689e720bbe0fe5cbadb4.png "z=z_0+\frac B{\left[ 1+\left( \frac xC\right) ^{-D}\right] \left[ 1+\left( \frac yE\right) ^{-F}\right] }")
|
| Exponential2D(x,y,z0,B,C,D)
|
2D指数減少関数
")
|
| Extreme2D(x,y,z0,B,C,D,E,F)
|
非線形極値関数
![\begin{aligned}z=&z_0+By+Cy^2+D\exp \Bigg[ 1-\exp \left( \frac{E-x}F\right) -\\
&\frac{x-E}F\Bigg] \end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-a0c9ce975318fafdf4138b076211c01e.png "\begin{aligned}z=&z_0+By+Cy^2+D\exp \Bigg[ 1-\exp \left( \frac{E-x}F\right) -\\
&\frac{x-E}F\Bigg] \end{aligned}")
|
| ExtremeCum(x,y,z0,B,C,D,E,F,G,H)
|
非線形極値累積関数

|
| Fourier2D(x,y,z0,a,b,c,d,w1,w2)
|
2つの変数の正弦と余弦関数の合計
 +b\sin \left( \frac x{w_1}\right) +c\cos \left( \frac y{w_2}\right) +\\
&d\sin \left( \frac y{w_2}\right)\end{aligned}")
|
| Gauss2D(x,y,z0,A,xc,w1,yc,w2)
|
ガウス曲面
 ^2-\frac 12\left( \frac{y-y_c}{w_2}\right) ^2\right\}")
|
| GaussCum(x,y,z0,B,C,D,E,F)
|
2Dガウス累積関数
![\begin{aligned}z=&z_0+0.25B\left[1+{erf}\left\{\frac{x-C}{\sqrt{2}D}\right\}\right]\bigg[1+\\
&{erf}\left\{\frac{y-E}{\sqrt{2}F}\right\}\bigg]\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-720208e859a9ac6fb5b01b06e95e8197.png "\begin{aligned}z=&z_0+0.25B\left[1+{erf}\left\{\frac{x-C}{\sqrt{2}D}\right\}\right]\bigg[1+\\
&{erf}\left\{\frac{y-E}{\sqrt{2}F}\right\}\bigg]\end{aligned}")
|
| Gaussian2D(x,y,z0,A,xc,w1,yc,w2,theta)
|
回転ガウス曲面
+y\sin(\theta)-x_c\cos(\theta)+y_c\sin(\theta)}{w_1}\bigg)^2-\\
&\frac 12\bigg(\frac{-x\sin(\theta)+y\cos(\theta)+x_c\sin(\theta)-y_c\cos(\theta)}{w_2}\bigg)^2\bigg\}\end{aligned}")
|
| LogisticCum(x,y,z0,B,C,D,E,F)
|
非線形シグモイド(ロジスティック累積)関数
![z=z_0+\frac B{\left[ 1+\exp \left\{ \frac{C-x}D\right\} \right] \big[ 1+\exp \big\{ \frac{E-y}F\big\} \big] }](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-32a77cf59f1fefd1e2ce0e84f3bf73fe.png "z=z_0+\frac B{\left[ 1+\exp \left\{ \frac{C-x}D\right\} \right] \big[ 1+\exp \big\{ \frac{E-y}F\big\} \big] }")
|
| LogNormal2D(x,y,z0,B,C,D,E,F,G,H)
|
2D対数正規関数。
 ^2}{2D^2}\right\} +E\exp \left\{ -\frac{\left( \ln \frac yF\right) ^2}{2G^2}\right\}+\\
&H\exp \left\{ -\frac{\left( \ln \frac xC\right) ^2}{2D^2}-\frac{\left( \ln \frac yF\right)^2 }{2G^2}\right\}\end{aligned}")
|
| Lorentz2D(x,y,z0,A,xc,w1,yc,w2)
|
非線形シグモイド(ロジスティック累積)関数
![z=z_0+\frac A{\left[ 1+\left( \frac{x-x_c}{w_1}\right) ^2\right] \left[ 1+\left( \frac{y-y_c}{w_2}\right) ^2\right] }](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-285d961d27715d22e87d343a2be517aa.png "z=z_0+\frac A{\left[ 1+\left( \frac{x-x_c}{w_1}\right) ^2\right] \left[ 1+\left( \frac{y-y_c}{w_2}\right) ^2\right] }")
|
| Parabola2D(x,y,z0,a,b,c,d)
|
xy項のない2Dパラボラ関数

|
| Plane(x,y,z0,a,b)
|
平面

|
| Poly2D(x,y,z0,a,b,c,d,f)
|
2D二次多項式

|
| Polynomial2D(x,y,z0,A1,A2,A3,A4,A5,B1,B2,B3,B4,B5)
|
交差項なしの2D五次多項式

|
| Power2D(x,y,z0,B,C,D,E,F)
|
2D Power関数

|
| Rational2D(x,y,z0,A01,B01,B02,B03,A1,A2,A3,B1,B2)
|
3次の分子と3次の分母を持つ2D Rational関数

|
| RationalTaylor(x,y,z0,A01,B01,B02,C02,A1,A2,B1,B2,C2)
|
Taylor系列のRational関数

|
| Voigt2D(x,y,z0,A,xc,w1,yc,w2,mu)
|
Voigt曲面
![\begin{aligned}z=&z_0+A\Bigg[\frac{\mu\!}{\left[1+\left(\frac{x-x_c}{w_1}\right)^2\right]\left[1+\left(\frac{y-y_c}{w_2}\right)^2\right]}
+\\
&(1-\mu\!)\exp\left(-\frac{1}{2}\left(\frac{x-x_c}{w_1}\right)^2-\frac{1}{2}\left(\frac{y-y_c}{w_2}\right)^2\right)\Bigg]\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-4dc3ec1c5687631274f03b0d75c247b4.png "\begin{aligned}z=&z_0+A\Bigg[\frac{\mu\!}{\left[1+\left(\frac{x-x_c}{w_1}\right)^2\right]\left[1+\left(\frac{y-y_c}{w_2}\right)^2\right]}
+\\
&(1-\mu\!)\exp\left(-\frac{1}{2}\left(\frac{x-x_c}{w_1}\right)^2-\frac{1}{2}\left(\frac{y-y_c}{w_2}\right)^2\right)\Bigg]\end{aligned}")
|
| Voigt2DMod(x,y,z0,A,xc,w1,yc,w2,mu)
(2016 SR0)
|
パラメータとして体積のあるvoigt 曲面
![\begin{aligned}z=&z0+A\Bigg[\frac{mu}{(1+((x-xc)/w1)^2)*(1+((y-yc)/w2)^2)} +\\ &(1-mu)*exp(-\frac{1}{2}*(\frac{x-xc}{w1})^2-\frac{1}{2}*(\frac{y-yc}{w2})^2)\Bigg]\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-1255c4dc06f394fbd52ac23a2d40c4cb.png "\begin{aligned}z=&z0+A\Bigg[\frac{mu}{(1+((x-xc)/w1)^2)*(1+((y-yc)/w2)^2)}
+\\
&(1-mu)*exp(-\frac{1}{2}*(\frac{x-xc}{w1})^2-\frac{1}{2}*(\frac{y-yc}{w2})^2)\Bigg]\end{aligned}")
|
PFW
| 名前
|
説明
|
| Asym2Sig(x,y0,xc,A,w1,w2,w3)
|
非対称の2重シグモイド
")
|
| Bigaussian(x,y0,xc,H,w1,w2)
|
非対称ピークのフィットに使用する二重Gaussianピーク関数
|
| BWF(x,y0,xc,H,w,q)
|
Breit-Wigner-Fano (BWF) 線形
 ^2}{1+\left( \frac{x-x_c}w\right) ^2}")
|
| CCE(x,y0,xc1,A,w,k2,xc2,B,k3,xc3)
|
クロマトグラフィで使われるChesler-Cramピーク関数
^2}{2w}}+")
![B(1-0.5(1-\tanh (k_2(x-x_{c2}))))e^{-0.5k_3(|x-x_{c3}|+(x-x_{c3}))}]](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-57b6cef7f7567fd6ee984db95247d48c.png "B(1-0.5(1-\tanh (k_2(x-x_{c2}))))e^{-0.5k_3(|x-x_{c3}|+(x-x_{c3}))}]")
|
| ConsGaussian(x,y0, xc, A, w1, w2)
|
制約付きGaussian関数
 ^2}{\left( w_1+w_2x_c\right)^2 }}}{\left( w_1+w_2x_c\right) \sqrt{2\pi }}")
|
| DoniachSunjic(x,y0, xc, H, w, a)
|
Doniach Sunjic関数
 \arctan \left( \frac{x-x_c}w\right) \right) }{\sqrt{\left( w^2+\left( x-x_c\right) ^2\right) ^{\left( 1-a\right) }}}")
|
| ECS(x,y0,xc,A,w,a3,a4)
|
クロマトグラフィで使われるEdgeworth-Cramerピーク関数
+\frac{a_4}{4!}(z^4-\\&6z^3+3)+\frac{10a_3^2}{6!}\left(z^6-15z^4+45z^2-15\right)\bigg)\\
z=&\frac{x-x_c}w\end{aligned}")
|
| FraserSuzuki(x,y0,xc,A,sig)
|
FraserSuzuki 非対称関数
 ^2}{2sigL}}}{sig\sqrt{2\pi }}") ")
 ^2}{2sigR}}}{sig\sqrt{2\pi }}") ")
ここで
") , ,")
|
| Gauss(x, y0, xc, w, A)
|
ガウス関数の面積バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 面積)
|
| GaussAmp(x,y0,xc,w,A)
|
ガウスピーク関数の振幅バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 振幅)
|
| Gaussian(x,y0,xc,A,w)
|
ガウス関数のFWHMバージョン
(y0 = ベースライン, xc = 中心, A = 面積, w = FWHM)
|
| Gaussian_LorenCross(x,y0, xc, A, w, s)
|
Gaussian-Lorentzian クロス積
 \left( x-x_c\right) ^2}ws\left( x-x_c\right) ^2}}{w^2}}")
|
| GaussMod(x,y0,A,xc,w,t0)
|
クロマトグラフィで使用される指数修正ガウス(EMG)ピーク関数
|
| GCAS(x,y0,xc,A,w,a3,a4)
|
クロマトグラフィで使われるGram-Charlierピーク関数
 =y_0+\frac A{w\sqrt{2\pi }}e^{\frac{-z^2}2}\left( 1+\left|\sum_{i=3}^4\frac{a_i}{i!}H_i\left( z\right)\right| \right)\\
&z=\frac{x-x_c}w, H_3=z^3-3z, H_4=z^4-6z^2+3\end{aligned}")
|
| HVL(x, y0, xc, A, w, d)
|
Haaroff-Van der Linde 関数
 ^2}{w^2}}w}{d\sqrt{2\pi }x_c\left( e^{1-\frac{dx_c}{w^2}}+0.5\left( 1+Erf\left( \frac{x-x_c}{w\sqrt{2}}\right) \right) \right) }")
|
| InvsPoly(x,y0,xc,w,A,A1,A2,A3)
|
中心の逆多項式ピーク関数
|
| LogNormal(x,y0,xc,w,A)
|
対数が正規分布するランダム変数の確率密度関数
|
| Lorentz(x, y0, xc, w, A)
|
ベル型でGaussian関数より幅の広いLorentzianピーク関数
(y0 = オフセット, xc = 中心, w = FWHM, A = 面積)
|
| PearsonVII(x,y0,xc,A,w,m)
|
ピアソンのタイプVIIピーク関数、べき乗されたローレンツ関数。
|
| PsdVoigt1(x,y0,xc,A,w,mu)
|
擬フォークト(Pseudo-Voigt)関数。Gaussian関数とLorentzian関数の線形混合
(y0 = オフセット, xc = 中心, A = 面積, w = FWHM, mu = プロファイル形要因)
|
| PsdVoigt2(x,y0,xc,A,wG,wL,mu)
|
擬フォークト(Pseudo-Voigt)関数。異なるFWHMのGaussian関数とLorentzian関数の線形混合
(y0 = オフセット, xc = 中心, A =面積, wG=Gaussian FWHM, wL=Lorentzian FWHM, mu = プロファイル形要因)
![\begin{aligned}y=&y_0+A\bigg[ m_u\frac 2\pi \frac{w_L}{4\left( x-x_c\right) ^2+w_L^2}+\\
&\left( 1-m_u\right) \frac{\sqrt{4\ln 2}}{\sqrt{\pi}w_G}e^{-\frac{4\ln 2}{w_G^2}\left( x-x_c\right) ^2}\bigg] \end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-a7026ad226684f46e4581ae2a80929b1.png "\begin{aligned}y=&y_0+A\bigg[ m_u\frac 2\pi \frac{w_L}{4\left( x-x_c\right) ^2+w_L^2}+\\
&\left( 1-m_u\right) \frac{\sqrt{4\ln 2}}{\sqrt{\pi}w_G}e^{-\frac{4\ln 2}{w_G^2}\left( x-x_c\right) ^2}\bigg] \end{aligned}")
|
| Pulse(x,y0,x0,A,t1,P,t2)
|
指数パルス関数(x >= x0 ? y : 0)
|
| SchulzFlory(x,y0,xc,w,A)
|
重合の後ポリマーの相関的比率を説明するためのSchulz Flory分布関数
^{\frac{x_c}{w}}")
|
| Sine(x,xc,w,A,y0)
|
特定の値の周囲で振動するSin波関数
")
|
| SineDamp(x,y0,xc,w,t0,A)
|
正弦波収束関数。時間経過とともに振幅が減少する正弦波関数
")
 , ,  , , 
|
| Sinesqr(x,xc,w,A,y0)
|
Sin二乗関数
|
| Voigt(x,y0,xc,A,wG,wL)
|
Gaussian関数(wG は FWHM) と Lorentzian 関数のコンボリューション
(y0 = オフセット, xc = 中心, A =面積, wG = Gaussian FWHM, wL = Lorentzian FWHM)
 ^2+\left( \sqrt{4\ln 2}\frac{x-x_c}{W_G}-t\right) ^2}dt")
|
| Weibull3(x,y0,xc,A,w1,w2)
|
ワイブルピーク関数の振幅バージョン
 ^{\frac 1{w_2}}")
![y=y_0+A\left( \frac{w_2-1}{w_2}\right) ^{\frac{1-w_2}{w_2}}\left[ S\right] ^{w_2-1}e^{-\left[ S\right] ^{w_2}+\left( \frac{w_2-1}{w_2}\right) }](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-2566aad3afe36e3faadff13e4072dcd8.png "y=y_0+A\left( \frac{w_2-1}{w_2}\right) ^{\frac{1-w_2}{w_2}}\left[ S\right] ^{w_2-1}e^{-\left[ S\right] ^{w_2}+\left( \frac{w_2-1}{w_2}\right) }")
|
Baseline
| 名前
|
説明
|
| Constant(x,y0)
|
定数の線形関数
|
| Cubic(x,A,B,C,D)
|
3次の多項式
|
| ExpDec1(x,y0,A1,t1)
|
一定時間パラメータの1次指数減少関数
|
| ExpDec2(x,y0,A1,t1,A2,t2)
|
一定時間パラメータの2次指数減少関数
|
| ExpGro1(x,y0,A1,t1)
|
一定時間パラメータの1次指数増加関数
|
| ExpGrow1(x,y0,x0,A1,t1)
|
時間オフセット付き1次指数増加関数。x0は固定。
|
| ExpGrow2(x, y0, x0, A1, t1, A2, t2)
|
時間オフセット付き2次指数増加関数。x0は固定。
|
| Exponential(x,y0,A,R0)
|
一定率パラメータの指数増加関数
|
| Hyperbl(x, P1, P2)
|
双曲線関数、酵素反応速度論のMichaelis-Mentenモデル
|
| Line(x,A,B)
|
傾きと切片を持つ線形関数
|
| MnMolecular(x,A,xc,k),
|
単分子の成長関数
|
| Parabola(x,A,B,C)
|
2次の多項式
|
| Poly4(x,A0,A1,A2,A3,A4)
|
4次多項式関数
|
| Poly5(x,A0,A1,A2,A3,A4,A5)
|
5次多項式関数
|
| Step(x,A,B,x1)
|
2つの区分のPiecewise 定数関数
|
Chromatograph
| 名前
|
説明
|
| CCE(x,y0,xc1,A,w,k2,xc2,B,k3,xc3)
|
クロマトグラフィで使われるChesler-Cramピーク関数
|
| ECS(x,y0,xc,A,w,a3,a4)
|
クロマトグラフィで使われるEdgeworth-Cramerピーク関数
|
| Gauss(x, y0, xc, w, A)
|
ガウス関数の面積バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 面積)
|
| GaussMod(x,y0,A,xc,w,t0)
|
クロマトグラフィで使用される指数修正ガウス(EMG)ピーク関数
|
| GCAS(x,y0,xc,A,w,a3,a4)
|
クロマトグラフィで使われるGram-Charlierピーク関数
|
| Giddings(x,y0,xc,w,A)
|
クロマトグラフィで使われるGiddingsrピーク関数
|
Electrophysiology
| 名前
|
説明
|
| BoltzIV(x,vhalf,dx,gmax,vrev)
|
IVデータに対する変換済みボルツマン関数
|
| Boltzmann(x, A1, A2, x0, dx)
|
Boltzmann関数 - シグモイド曲線を生成します。
|
| DoubleBoltzmann(x,y0,A,frac,x01,x02,k1,k2)
|
二重Boltzmann関数。2つのBoltzmann関数の合計
|
| ExpDec1(x,y0,A1,t1)
|
一定時間パラメータの1次指数減少関数
|
| ExpDec2(x,y0,A1,t1,A2,t2)
|
一定時間パラメータの2次指数減少関数
|
| ExpDec3(x,y0,A1,t1,A2,t2,A3,t3)
|
一定時間パラメータの3次指数減少関数
|
| Gauss(x, y0, xc, w, A)
|
ガウス関数の面積バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 面積)
|
| Goldman(x,b,Nao,Nai,Ki,T)
|
電気生理学のGoldman-Hodgkin-Katz の式
![\begin{aligned}&E=\frac{RT}F\ln \left( \frac{\left[ K\right] _0+b\left[ Na\right] _0}{\left[ K\right] _i+b\left[ Na\right] _i}\right)\\
&x=\left[ K\right] _0,~ y=E\\
&R=8.314,F=96485,b=P_k/P_{Na}\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-4348b72101a80ee8c917fa817441cee7.png "\begin{aligned}&E=\frac{RT}F\ln \left( \frac{\left[ K\right] _0+b\left[ Na\right] _0}{\left[ K\right] _i+b\left[ Na\right] _i}\right)\\
&x=\left[ K\right] _0,~ y=E\\
&R=8.314,F=96485,b=P_k/P_{Na}\end{aligned}")
|
| Hill(x,Vmax,k,n)
|
配位子濃度と結合部位の最大数を決定するHill関数
|
Pharmacology
| 名前
|
説明
|
| BiDoseResp(x,A1,A2,LOGx01,LOGx02,h1,h2,p)
|
二相容量応答関数
|
| Biphasic(x,Amin,Amax1,Amax2,x0_1,x0_2,h1,h2)
|
二相シグモイド用量反応(7つのパラメータのロジスティック方程式)
}{1+10^{(x-x0\_1)h_1}}+
\frac{(A_{\max 2}-A_{\min })}{1+10^{(x0\_2-x)h_2}}")
|
| DoseResp(x,A1,A2,LOGx0,p)
|
パラメータ'p'によって与えられた変数Hill傾きの容量応答曲線
 p}}")
|
| MichaelisMenten(x,Vmax,Km)
|
酵素動力学の基本モデル。単一基質 Michaelis-Menten関数。
|
| OneSiteBind(x,Bmax,k1)
|
片側直接結合。直角双曲線が等温線や飽和率曲線に接続します。

|
| OneSiteComp(x,A1,A2,logx0)
|
片側競争曲線。Hill傾斜が-1のDose-response曲線
 }}")
|
| TwoSiteBind(x,Bmax1,Bmax2,k1,k2)
|
両側結合関数

|
| TwoSiteComp(x,A1,A2,logx0_1,logx0_2,fraction)
|
2種の受容器のための配位子の競合を説明する両側競合関数
 f}{1+10^{\left( x-\log x_{0\_1}\right) }}+\frac{\left( A_1-A_2\right) \left( 1-f\right) }{1+10^{\left( x-\log x_{0\_2}\right) }}")
|
Rheology
| 名前
|
説明
|
| Bingham(x,y0,A)
(2015 SR0)
|
降伏応答を示す粘塑性流体を記述するBinghamモデル。

|
| Cross(x,A1,A2,t,m)
(2015 SR0)
|
ゼロおよび無限のせん断速度で漸近粘度をもつ擬塑性流動を記述するクロスモデル。
^{m}}")
|
| Carreau(x,A1,A2,t,a,n)
(2015 SR0)
|
ゼロおよび無限のせん断速度で漸近粘度をもつ擬塑性流動を記述するCarreau-Yasudaモデル。
![y=A_{2}+(A_{1}-A_{2})[1+(tx)^{a}]^{\frac{n-1}{a}}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-2a5e177df5333db67ca1608b920108fd.png "y=A_{2}+(A_{1}-A_{2})[1+(tx)^{a}]^{\frac{n-1}{a}}")
|
| Herschel(x,y0,K,n)
(2015 SR0)
|
ベキ乗関係を示す粘塑性材料を記述する Herschel-Bulkley モデル

|
| VFT(x,A,B,x0)
(2015 SR0)
|
Vogel-Fulcher-Tammannの式

|
| MYEGA(x,y0,K,C)
(2015 SR0)
|
Mauro-Yue-Ellison-Gupta-Allanの式

|
Enzyme Kinetics
| 名前
|
説明
|
| CompInhib(x,Vmax,Km,Ki,Ic)
(2015 SR0)
|
1つの基盤と1つの阻害の競合阻害モデル
+x}")
この関数は通常グローバルフィットで使用され、各データセットにおいてVmax, Km, Kiは共有、Ic は固定です。Kiの初期値はIcの平均にすることができます。
|
| NoncompInhib(x,Vmax,Km,Ki,Ic)
(2015 SR0)
|
1つの基盤と1つの阻害の非競合阻害モデル
(K_\text{m}+x)}")
この関数は通常グローバルフィットで使用され、各データセットにおいてVmax, Km, Kiは共有、Ic は固定です。Kiの初期値はIcの平均にすることができます。
|
| UncompInhib(x,Vmax,Km,Kia,Ic)
(2015 SR0)
|
1つの基盤と1つの阻害の不競合阻害モデル
(\frac{K_\text{m}}{1+\frac{I_\text{c}}{K_\text{ia}}}+x)}")
この関数は通常グローバルフィットで使用され、各データセットにおいてVmax, Km, Kiaは共有、Ic は固定です。Kiaの初期値はIcの平均にすることができます。
|
| MixedModelInhib(x,Vmax,Km,Ki,Alpha,Ic)
(2015 SR0)
|
特殊なケースとして、競合、不競合および非競合阻害を含む一般的な方程式。
}}{x+\frac{K_m(1+I_c/K_i)}{1+I_c/(Alpha \cdot K_i)}}")
この関数は通常グローバルフィットで使用されます。これを使用する場合、Vmax, Km, Ki, Alpha は共有し、Ic は定数で固定します。Kiの初期値はIcの平均にすることができます。
|
| SubstrateInhib(x,Vmax,Km,Ki)
(2015 SR0)
|
高濃度の基質阻害モデル
}")
|
| MichaelisMenten(x,Vmax,Km)
|
酵素動力学の基本モデル。単一基質 Michaelis-Menten関数。
|
| Hill(x,Vmax,k,n)
|
配位子濃度と結合部位の最大数を決定するHill関数
|
Spectroscopy
| 名前
|
説明
|
| GaussAmp(x,y0,xc,w,A)
|
ガウスピーク関数の振幅バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 振幅)
|
| InvsPoly(x,y0,xc,w,A,A1,A2,A3)
|
中心の逆多項式ピーク関数
|
| Lorentz(x, y0, xc, w, A)
|
ベル型でGaussian関数より幅の広いLorentzianピーク関数
(y0 = オフセット, xc = 中心, w = FWHM, A = 面積)
|
| PearsonVII(x,y0,xc,A,w,m)
|
ピアソンのタイプVIIピーク関数、べき乗されたローレンツ関数。
|
| PsdVoigt1(x,y0,xc,A,w,mu)
|
擬フォークト(Pseudo-Voigt)関数。Gaussian関数とLorentzian関数の線形混合
(y0 = オフセット, xc = 中心, A = 面積, w = FWHM, mu = プロファイル形要因)
![\begin{aligned}y=&y_0+A\bigg[ m_u\frac 2\pi \frac w{4\left( x-x_c\right) ^2+w^2}+\\
&\left( 1- m_u\right) \frac{\sqrt{4\ln 2}}{\sqrt{\pi}w}e^{-\frac{4\ln 2}{w^2}\left( x-x_c\right) ^2}\bigg] \end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-054a79b30e4c7feda522b89c192979bc.png "\begin{aligned}y=&y_0+A\bigg[ m_u\frac 2\pi \frac w{4\left( x-x_c\right) ^2+w^2}+\\
&\left( 1- m_u\right) \frac{\sqrt{4\ln 2}}{\sqrt{\pi}w}e^{-\frac{4\ln 2}{w^2}\left( x-x_c\right) ^2}\bigg] \end{aligned}")
|
| PsdVoigt2(x,y0,xc,A,wG,wL,mu)
|
擬フォークト(Pseudo-Voigt)関数。異なるFWHMのGaussian関数とLorentzian関数の線形混合
(y0 = オフセット, xc = 中心, A =面積, wG=Gaussian FWHM, wL=Lorentzian FWHM, mu = プロファイル形要因)
![\begin{aligned}y=&y_0+A\bigg[ m_u\frac 2\pi \frac{w_L}{4\left( x-x_c\right) ^2+w_L^2}+\\
&\left( 1-m_u\right) \frac{\sqrt{4\ln 2}}{\sqrt{\pi}w_G}e^{-\frac{4\ln 2}{w_G^2}\left( x-x_c\right) ^2}\bigg]\end{aligned}](//d2mvzyuse3lwjc.cloudfront.net/doc/ja/LabTalk/images/LabTalk-Supported_Functions/math-c222b784c08a7133e8cd95fac7d804fa.png "\begin{aligned}y=&y_0+A\bigg[ m_u\frac 2\pi \frac{w_L}{4\left( x-x_c\right) ^2+w_L^2}+\\
&\left( 1-m_u\right) \frac{\sqrt{4\ln 2}}{\sqrt{\pi}w_G}e^{-\frac{4\ln 2}{w_G^2}\left( x-x_c\right) ^2}\bigg]\end{aligned}")
|
| Voigt(x,y0,xc,A,wG,wL)
|
Gaussian関数(wG は FWHM) と Lorentzian 関数のコンボリューション
|
統計
| 名前
|
説明
|
| Exponential(x,y0,A,R0)
|
一定率パラメータの指数増加関数
|
| ExponentialCDF(x,y0,A,mu)
(2016 SR0)
|
Exponential 累積分布関数
&x\geq 0\\
y_0&x< 0
\end{cases}")
|
| Extreme(x,y0,xc,w,A)
|
特例のExtreme関数。Gumbel確率密度関数
|
| GammaCDF(x,y0,A1,a,b)
(2016 SR0)
|
Gamma 累積分布関数
}\int_{0}^{x}t^{a-1}e^{-\frac{t}{b}}dt\; \; \; x>0")
|
| Gauss(x, y0, xc, w, A)
|
ガウス関数の面積バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 面積)
|
| GaussAmp(x,y0,xc,w,A)
|
ガウスピーク関数の振幅バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 振幅)
|
| Gumbel(x,a,b)
|
変換Gumbel累積分布関数

|
| Laplace(x,y0,a,b)
|
ラプラス確率密度関数
|
| Logistic(x, A1, A2, x0, p)
|
薬理学/化学でのロジスティック用量応答。4PL または 4PLC とも呼ばれます。
|
| LogNormal(x,y0,xc,w,A)
|
対数が正規分布するランダム変数の確率密度関数
|
| LognormalCDF(x,y0,A,xc,w)
(2016 SR0)
|
LognormalCDF 累積分布関数
-x_c)^2}{2w^2}}dt")
|
| Lorentz(x, y0, xc, w, A)
|
ベル型でGaussian関数より幅の広いLorentzianピーク関数
(y0 = オフセット, xc = 中心, w = FWHM, A = 面積)
|
| NormalCDF(x,y0,A,xc,w)
|
通常の累積分布関数
( y0 = オフセット, A = 振幅, xc = 平均, w = 標準偏差)
^2}{2w^2}}dt")
|
| Pareto(x,A)
|
1つのパラメータのPareto累積密度関数。冪乗則確率分布
|
| Pareto2(x,a,b)
|
2つのパラメータのPareto関数
 ^a")
|
| PearsonIV(x,y0,A,m,v,alpha,lam)
|
負の判別子のためのピアソンのタイプIV分布。偏りのある分布に適合しやすい。
|
| Poisson(x,y0,r)
|
Poisson確率密度関数。離散確率分布
|
| Rayleigh(x,b)
|
Rayleigh 累積分布関数

|
| Weibull(x,y0,a,r,u)
|
Weibull確率密度関数
 ^{b-1}\exp \left\{-\left( \frac{x-c}a\right) ^b\right\}")
|
| WeibullCDF(x,y0,A1,a,b)
(2016 SR0)
|
Weibull累積分布関数
^b}dt\\
=y_0+A_1\left ( 1- e^{-\left (\frac{x}{a}\right)^b}\right )&x>0\\
y_0 & x\leq 0
\end{cases}")
|
Quick Fit
| 名前
|
説明
|
| Boltzmann(x, A1, A2, x0, dx)
|
Boltzmann関数 - シグモイド曲線を生成します。
/(1 + e^{(x-x_0)/dx})")
|
| DoseResp(x,A1,A2,LOGx0,p)
|
パラメータ'p'によって与えられた変数Hill傾きの容量応答曲線
|
| ExpDecay1(x,y0,x0,A1,t1)
|
時間オフセット付き1次指数減少 。x0は修正。
|
| ExpGrow1(x,y0,x0,A1,t1)
|
時間オフセット付き1次指数増加関数。x0は固定。
|
| Gauss(x, y0, xc, w, A)
|
ガウス関数の面積バージョン
(y0 = オフセット, xc = 中心, w = 幅, A = 面積)
}e^{-2\left(\frac{x-xc}{w}\right)^2}")
|
| Hill(x,Vmax,k,n)
|
配位子濃度と結合部位の最大数を決定するHill関数
|
| Hyperbl(x, P1, P2)
|
双曲線関数、酵素反応速度論のMichaelis-Mentenモデル
|
| Logistic(x, A1, A2, x0, p)
|
薬理学/化学でのロジスティック用量応答。4PL または 4PLC とも呼ばれます。
^p}")
|
| Lorentz(x, y0, xc, w, A)
|
ベル型でGaussian関数より幅の広いLorentzianピーク関数
(y0 = オフセット, xc = 中心, w = FWHM, A = 面積)
|
| Sine(x,y0,xc,w,A)
|
特定の値の周囲で振動するSin波関数
|
| Voigt(x,y0,xc,A,wG,wL)
|
Gaussian関数(wG は FWHM) と Lorentzian 関数のコンボリューション
|
Multiple Variables
| 名前
|
説明
|
| GaussianLorentz(y0, xc, A1, A2, w1, w2)
|
1つの独立変数と2つの従属変数、共有パラメータ
^2}")
^2 + w_2^2)}")
|
| Helix(x,x0,y0,A,w,p)
|
3D Helix 関数
 + x_{0}")
 + y_{0}")
|
| HillBurk(Vm1, Km1, Vm2, Km2)
|
2つの独立した変数と2つの従属変数を持つHillとBurkモデルの組み合わせ。


|
| Line3(a, b, c, d)
|
傾斜と切片を持つ3D Line関数


|
| LineExp(x,Vmax,k,n)
|
1つの独立変数と2つの従属変数を持つ線と指数モデルの組み合わせ。


|
その他
| 名前
|
説明
|
| BitAND(n1, n2)
|
2つの整数のビット積を返します。
|
| BitOR(n1, n2)
|
2つの整数のビット和を返します。
|
| BitXOR(n1, n2)
|
2つの整数のビット排他的和を返します。
|
| ISNA(d)
|
数字が NANUMかどうか判定します。
|
| isText(str$)
(2019)
|
値がテキストかどうかを判定します。値がテキストかどうかを判定します。テキストの場合1または空欄、数値の場合NANUMを返します。
|
| Let(var1,val1[,var2,val2,]...[,var39, val39], expression)[$]
(2021)
|
ExcelのLET()関数に似ています。式で使用するために、最大39の変数と値のペアの変数(valN)に値(varN)を割り当てます。オプションの$は文字列を返すときに使用されます。サンプル:
-
LET(t,if(A$==B$,1,0/0),t*500) 2つの文字列が一致しない場合は欠落値( "-")を返し、一致しない場合は "500"を返します。
-
LET(first,left(A,1),last,left(B,2), first$+ "-" + last$) 2つの文字列を「-」区切り文字で連結します。
|
| NA()
|
NANUMを返します。
|
| ocolor2rgb(oColor)
(2019 SR0)
|
内部カラーコードoColorをRGB値に変換します。
|
| xf_get_last_error_code()
|
Xファンクションエンジンの最後のエラーコードの値を取得します。
|
| xf_get_last_error_message()$
|
Xファンクションエンジンの最後のエラーメッセージを取得します。
|
| xor(n1,n2)
(2019 SR0)
|
2つの論理値n1とn2のXOR演算を返します。サンプル
XOR(1>0,7>2) 両方がtrueのため、0を返します。XOR(1<0,7<2) 両方ともFALSEであるため、0を返します。XOR(1>0,7<2) 1番目のTRUEと2番目のFALSEのため、1を返します。
|
工学
複素数
経済
使用上の注意
それぞれの関数は、関数のタイプと与えられた引数により、一つの値、あるいは、ある範囲の値(データセット)のどちらかを返します。そうでない場合、何も指定がなければ、すべての関数は、渡される最初の引数が範囲の場合、範囲を返し、値の場合、値を返します。
|