17.2.4 Probability Plot and Q-Q PlotProbPlot-QQPlot
The probability plot is used to test whether a dataset follows a given distribution. It shows a graph with an observed cumulative percentage on the X axis and an expected cumulative percentage on the Y axis. If all the scatter points are close to the reference line, we can say that the dataset follows the given distribution.
A Q-Q (Quantile-Quantile) plot is another graphic method for testing whether a dataset follows a given distribution. It differs from the probability plot in that it shows observed and expected values instead of percentages on the X and Y axes. If all the scatter points are close to the reference line, we can say that the dataset follows the given distribution.
Origin supports five given distributions (Normal, Lognormal, Exponential, Weibull and Gamma), and five methods for plotting percentile approximations (Blom, Benard, Hazen, Van der Waerden, and Kaplan-Meier).
Creating Probability Plot or Q-Q Plot
To create a probability plot or Q-Q plot:
- Highlight one Y column or multiple Y columns as input variable(s).
- Open the probability/Q-Q plot dialog:
- For a probability plot: In Origin's main menu, click Plot > Statistical: Probability Plot.... Alternatively, you can click the Probability Plot button
 on the 2D Graphs toolbar. on the 2D Graphs toolbar.
- For a Q-Q plot: In Origin's main menu, click 'Plot > Statistical: Q-Q Plot.... Alternatively, you can click the Q-Q Plot button
 on the 2D Graphs toolbar. on the 2D Graphs toolbar.
- In the plot_prob X-Function dialog, select the grouping column(s), set arrangement of groups and variables, choose a column to split the plot into panels, specify the distribution and method.
- Click OK to create a probability plot or a Q-Q plot.

As you can see, in this example,
- 2 columns selected in Input Data have been plotted into separate graphs through setting Multiple Data to Separate Graphs.
- The grouping column "country" selected in Group box has divided the probability plot into multiple plots overlaid on same graph.
- Another grouping column "Luxury" selected in Split Panels by box has separated the graph into two layers (N and Y).
- A table with statistics results have been added onto the graph.
The Dialog of plot_prob X-Function

|
Input Data
|
Specify the input data. You can select multiple columns as inout variables.
|
|
Group
|
Specify the grouping column(s) in order to seperate the input variable(s) into multiple different plots.
|
|
Graph Arrangement
|
The controls under this brach will help you arrange the multiple input variables and groups, split the graph into multiple panels and pages.
- Multiple Data and Multiple Groups:Use these two options , the plots will be arranged in these four ways:
- Overlay All: Both Multple Data and Multiple Group select Overlap on Same Graph.
- Overlay Groups, Variables in Different Layers: Multple Data=Separate Layers, Multiple Groups=Overlap on Same Graph
- Overlay Variables, Groups in Different Layers: Multiple Groups=Separate Layers, Multple Data=Overlap on Same Graph
- Different Layers: Both Multple Data and Multiple Groups select Separate Layers
- Split Panels by: Once this check box has been checked, you can select another grouping column to separate the graphs into multiple layers.
- Note: If Multiple Data and Multiple Groups both are set to Separate Layers, the layer order in result sheet should follow the hierarchy of "by Input Data" →"Split Panels by" → "by Groups"
- Split Pages by: Once this check box has been checked, you can select other grouping column(s) to split the input data and created probability plots in different graph pages. Each page only plots the columns within the same page related group. Page related group info will be shown in layer title, separated by comma if there are multiple factors. Report graph sheet will list all pages.
|
|
Share X Scales
|
Specify whether share X scales for all layers on same graph. This option is only available when Separate Layers on Same Graph selected in Multiple Data and Multiple Groups or grouping columns selected in Split Panels by box.
|
|
Share Y Scales
|
Specify whether share Y scales for all layers on same graph. This option is only available for Q-Q plot when Separate Layers on Same Graph selected in Multiple Data and Multiple Groups or grouping columns selected in Split Panels by box.
|
|
Distribution
|
Select a distribution type for your data. For more information about distributions, please refer to Distributions section.
- Distribution
- 14 distributions are available.

- Estimate from Data
- Specify whether to estimate distribution parameters from input data. If not, parameters can be specified manually.
- Parameters: Unchecking the Estimate from Data box activates the Parameters boxes, where you can enter custom values to draw the curves.
- You can check more details about distribution curves in the Distribution tab of Plot Details dialog.
|
|
Score Method
|
Select a method for plotting percentile approximations. For more information about methods, please refer to Score Methods section.
- Blom
- Benard
- Hazen
- Van der Waerden
- Kaplan-Meier
|
|
Confidence Band
|
Specify whether to output the confidence band in probability plot. For computation details, see Algorithms.
|
|
Confidence Level(%)
|
Only available when Confidence Band is selected. Specify the confidence level in percentage for the chosen distribution.
|
| Exchange X-Y Axes
|
Specify whether to switch X and Y axis positions.
|
X Minimum
X Maximum
|
By default, Auto boxes are checked, which means the minimum and maximum X values of the Reference Line columns in the result sheet "PlotData#" will be used to created the distribution curves.
Uncheck the Auto check box, you can enter the minimum and/or maximum of the X values for all distribution reference lines. All refence lines will be plotted within this X range.
|
|
Output Range
|
This determines where the calculated data for the graph is stored.
|
|
Output Graphs
|
This determines where the result graphs are stored.
|
Distributions
Origin includes four distributions for Probability and Q-Q plots. The following table lists their density functions:
| Distribution
|
Density Function p(x)
|
Range
|
Parameters
|
|
Normal
|
 ^2}{2\sigma ^2}\right)")
|
all 
|
 ,mean,is the location parameter ,mean,is the location parameter
") ,standard deviation, is the scale parameter ,standard deviation, is the scale parameter
|
|
Lognormal
|
 -\mu \right) ^2}{2\sigma ^2}\right)")
|

|
is the shape scale parameter
is the scale parameter.
|
|
Exponential
|
")
|
|
is the scale parameter.
|
|
Weibull
|
 ^{c-1}\exp \left( -\left( \frac x\sigma \right) ^c\right)")
|
|
is the scale parameter
") is the shape parameter is the shape parameter
|
|
Gamma
|
\sigma^c}x^{c -1} exp(-x/\sigma),")
|
|
is the scale parameter
is the shape parameter
|
Details for Constructing Probability Plot
To construct a probability plot, sort the observed dataset from smallest to largest:
![x[1]\le x[2]\le x[3]\le \cdots \le x[n-1]\le x[n]](//d2mvzyuse3lwjc.cloudfront.net/doc/en/UserGuide/images/Probability_Plot_and_Q-Q_Plot/math-5624a30d4c678dc72eae5846b1e79702.png?v=0 "x[1]\le x[2]\le x[3]\le \cdots \le x[n-1]\le x[n]") , ,  is the total number of the observed dataset. is the total number of the observed dataset.
The sorted observed values are represented on the plot by points whose X-coordinates are ![x[i]\](//d2mvzyuse3lwjc.cloudfront.net/doc/en/UserGuide/images/Probability_Plot_and_Q-Q_Plot/math-92f8cb93ad9350ca1ab67868f3667559.png?v=0 "x[i]\") and whose Y-coordinates are calculated using the Score Method. and whose Y-coordinates are calculated using the Score Method.
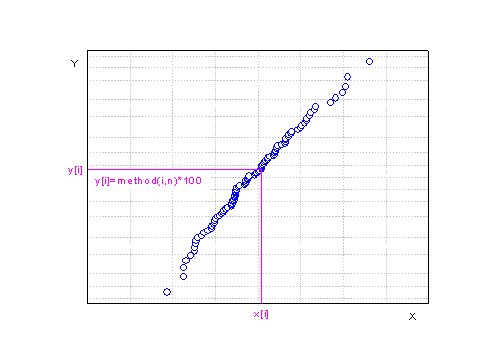
Scale types of probability plot are different according to the distributions
| Distribution
|
X Scale Type
|
Y Scale Type
|
|
Normal
|
Linear
|
Probability
|
|
Lognormal
|
Ln
|
Probability
|
|
Exponential
|
Ln
|
Double Log Reciprocal
|
|
Weibull
|
Log10
|
Double Log Reciprocal
|
|
Gamma
|
Log10
|
Probability
|
Details for Constructing Q-Q Plot
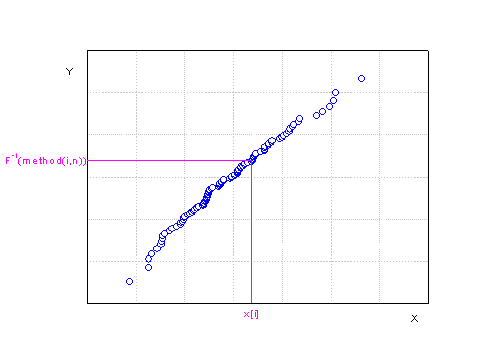
To construct a Q-Q plot,sort the observed dataset from smallest to largest:
- , where is the total number of observed values.
The Y values are the inverse cumulative distribution functions of the score method used.
Score Methods
Input data is ordered from smallest to largest, and then the serial number of the sorted data is scored using one of the methods listed below. In this table,  is the serial number and is the total number of the nonmissing input data. is the serial number and is the total number of the nonmissing input data.
| Methods
|
Plotting Position ")
|
|
Blom
|
/(n+0.25)")
|
|
Benard
|
/(n+0.4)")
|
|
Hazen
|
/n")
|
|
Van der Waerden
|
")
|
|
Kaplan-Meier
|

|
Reference
- Samuel Kotz , Campbell B. Read , N. Balakrishnan, Brani Vidakovic, 2005. Encyclopedia of statistical sciences., NewYork: John Wiley & Sons, Inc.
- Thode, Henry C. 2002, Testing for Normality, CRC Press
|