Algorithmus
Shapiro-Wilk-Test auf Normalverteilung
Bei einem gegebenen Satz von Beobachtungen 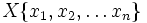 , der entweder in aufsteigender oder absteigender Reihenfolge sortiert ist, wird die Shapiro Wilk W-Statistik definiert als: , der entweder in aufsteigender oder absteigender Reihenfolge sortiert ist, wird die Shapiro Wilk W-Statistik definiert als:
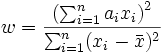
wobei
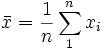
der Stichprobenmittelwert ist und ai, für i=1, 2,...n ein Satz von mathematischen Gewichtungen, deren Werte nur von der Stichprobengröße n abhängen.
Der Algorithmus, der von Origin verwendet wird, stammt aus dem von Patrick Royston beschriebenen Applied Statistics Algorithm R94 (1995). Die Funktion unterstützt Stichprobenumfänge von 3.
Der Freiheitsgrad (DF) ist gleich der Stichprobengröße.
Kolmogorov-Smirnov-Test auf Normalverteilung
Origin ruft eine NAG-Funktion auf, nag_1_sample_ks_test (g08cbc), um die Statistik zu berechnen. Bitte lesen Sie weitere Einzelheiten zu dem Algorithmus im entsprechenden NAG-Dokument nach.
Lilliefors-Test auf Normalverteilung
Der Lilliefors-Test ist eine Adaption des Kolmogorov-Smirnov-Tests. Die Statistik wird auf dieselbe Weise berechnet wie die Statistik des Kolmogorov-Smirnov-Tests. Der p-Wert ist jedoch unterschiedlich, da der Lilliefors-Test den Mittelwert und die Varianz der Daten nicht berücksichtigt, während der Kolmogorov-Smirnov-Test das tut. Die Methode nach Dallal und Wilkinson (1986) wird für die Berechnung des p-Werts verwendet.
Anderson-Darling-Test
Bei einem gegebenen Satz von Beobachtungen , der in aufsteigender Reihenfolge sortiert ist, wird die Anderson-Darling-Statistik definiert als:
A2 = - n - S
wobei
![S=\sum_{i=1}^n \frac{2i-1}{n}[lnF(x_i)+ln(1-F(x_n+1-i))]](//d2mvzyuse3lwjc.cloudfront.net/doc/de/UserGuide/images/math/f/7/c/f7cae3a1206f6f914d052dff890b633c.png)
F ist die kumulative Verteilungsfunktion der F-Verteilung.
D'Agostino-K
-
Schiefe-Statistik
- Die Schiefe
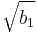 aus den Daten berechnen aus den Daten berechnen
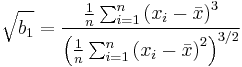
- Berechnen
![Y=\sqrt{b_1}[\frac{(n+1)(n+3)}{6(n-2)}]^{1/2}](//d2mvzyuse3lwjc.cloudfront.net/doc/de/UserGuide/images/math/0/8/7/0871490e98ec69fad467222dc80b74b0.png) 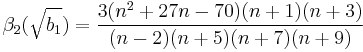 ![W^2=-1+[2(\beta_2(\sqrt{b_1})-1)]^{1/2}](//d2mvzyuse3lwjc.cloudfront.net/doc/de/UserGuide/images/math/9/0/d/90db371e86bad551a3cfed8e0dbf680d.png) 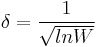 ![\alpha=[\frac{2}{(W^2-1)}]^{1/2}](//d2mvzyuse3lwjc.cloudfront.net/doc/de/UserGuide/images/math/d/6/3/d63ac64697d35d06cdd47a52125f5e4d.png)
- Die Schiefe-Statistik
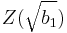 kann mit unten stehender Gleichung berechnet werden. kann mit unten stehender Gleichung berechnet werden.
![Z(\sqrt{b_1}) = \delta ln(Y/\alpha+[(Y/\alpha)^2+1]^{1/2})](//d2mvzyuse3lwjc.cloudfront.net/doc/de/UserGuide/images/math/4/e/1/4e1cfb36385a4ffedf50114481e39575.png)
-
Kurtosis-Statistik
- Die Kurtosis b2 aus den Daten berechnen
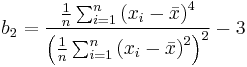
- Den Mittelwert und die Varianz von b2 berechnen
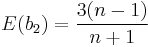 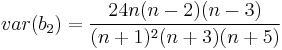
- Das standardisierte Moment of b2 berechen
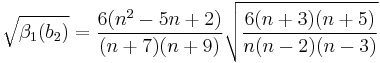
- Berechnen
![A=6+\frac{8}{\sqrt{\beta_1(b_2)}} [\frac{2}{\sqrt{\beta_1(b_2)}}+\sqrt{1+\frac{4}{\beta_1(b_2)}}]](//d2mvzyuse3lwjc.cloudfront.net/doc/de/UserGuide/images/math/f/a/7/fa757766541c4870fa3f3b00b607bded.png)
- Die Kurtosis-Statistik Z(b2) kann mit unten stehender Formel berechnet werden.
![Z(b_2)=((1-\frac{2}{9A})-[\frac{1-2/A}{1+x\sqrt{2/(A-4)}}]^{1/3})/\sqrt{2/(9A)}](//d2mvzyuse3lwjc.cloudfront.net/doc/de/UserGuide/images/math/2/c/a/2cab99d8e5986a8cd287fb87ce8b1497.png)
-
D'Agostino's Chi2 Statistic
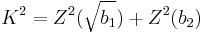
Chen-Shapiro-Test
Bei einem gegebenen Satz von Beobachtungen , der in aufsteigender Reihenfolge sortiert ist, wird Chen-Shapiro-Statistik definiert als:
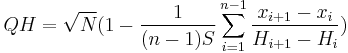
wobei
Hi = - 1((i - 3 / 8) / (n + 1 / 4)) und - 1 sind die Inverse der Standardnormalverteilung.
|