reducexy
メニュー情報
- ワークシート:データ削減:クラスタX
- 解析:データ操作:データ削減:クラスタX
概要
Xでサブグループの統計情報を使用してXYデータを削減
追加の情報
必要なOriginのバージョン: 8.1 SR0以降
2015 SR0でオプションが追加されています。
コマンドラインでの使用法
1. reducexy iy:=(col(A),col(B)) subgroup:=inc xincr:=0.5 xstats:=median
ystats:=min;
2. reducexy iy:=(col(A),col(B))
subgroup:=points points:=8 xstats:=ave ystats:=ave;
Xファンクションの実行オプション
スクリプトからXファンクションにアクセスする場合、追加のオプションスイッチについてのページを参照してください。
変数
表示
名 |
変数
名 |
I/O
と
データ型 |
デフォルト
値 |
説明 |
| 入力 |
iy |
入力
XYRange |
<active> |
入力データ範囲を指定します。 |
| サブグループ化の方法 |
subgroup |
入力
int |
0 |
ソースデータをサブグループに分割する方法を指定します。各グループのデータポイントがひとつのデータポイントに統合されます。
オプションリスト:
- 0=points:Nポイント毎
- 元データをNポイント毎にサブグループに分けます。Nの値はpoints 変数で指定できます。
- 1=groups:グループの数による
- groups 変数でm を指定します。そして、元データをm
グループに分けます。
- 2=inc:X増分による
- xincr 変数で増分を指定します。元データのX範囲を増分によってサブレンジに分割されます。各サブレンジのデータポイントがサブグループ分けされます。
- 3=ref:参照列による
- ref変数で増分を指定します。そして、元データを参照列によって分割します。
|
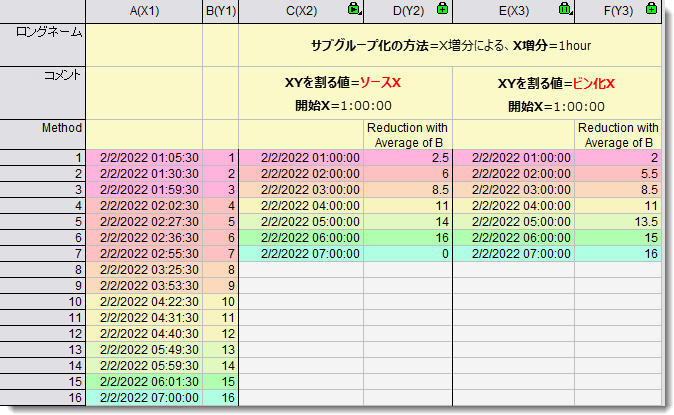
| XYを割る値 |
divide |
入力
int |
src |
サブグループ化の方法(subgroup)がグループの数による(roups) およびX増分による(inc)の場合に利用可能です。XYデータセットをどのようにサブグループにわけるか指定します。
オプションリスト:
- 0=src:ソースX
- サブグループの定義にソースのX値を使用します。開始X/終了XはX範囲出力を作成するために使用されます。
- 1=bin:ビン化X
- サブグループの定義を開始するために、X開始を最初のサブグループとして使用します。
- 2つのオプションの違いは以下のサンプルを参照してください。
 |
| N |
points |
入力
int |
<自動> |
これは、サブグループ化の方法でNポイント毎が選択されているときのみ利用できます。Nの値を指定します。入力範囲内のn個のデータポイントごとに1つのデータポイントに統合します。
|
| X増分値 |
xincr |
入力
double |
<auto> |
これは、サブグループ化の方法でX増分によるが選択されているときのみ利用できます。dx値を指定します。次に、同じグループに属する2つのデータポイントのX値の差がdxを超えないように、dxを使用して入力データポイントを複数のグループに分割します。グループ化後、データポイントの各グループは一つに統合されます。xincr
が指定されていないとき、式xincr = end-start / nsize
* 5(ここでnsize は入力データポイント数)によってデフォルト値が自動で計算されます。 |
| グループ |
groups |
入力
int |
<auto> |
これは、サブグループ化の方法でグループの数によるが選択されているときのみ利用できます。グループの数を指定します。
|
| 開始X |
start |
入力
double |
<auto> |
グループ化開始のX値を指定します。 |
| 終了X |
end |
入力
double |
<自動> |
グループ化終了のX値を指定します。 |
| 参照列 |
ref |
入力
Range |
<optional> |
サブグループ化の方法をref(参照列による)にした場合の参照列を指定します。 |
| X統合 |
xstats |
入力
int |
0 |
データポイントのグループが統合される出力データポイントのX値を取得する方法を指定します。
オプションリスト:
- ave:平均
- 各グループのデータポイントのX値の平均値を取得します。
- median:中央値
- 各グループのデータポイントのX値の中央値を取得します。
- first:サブグループの最初
- 各グループの最初のデータポイントのX値を取得します。
- last:サブグループの最後
- 各グループの最後のデータポイントのX値を取得します。
- xatminy:最小のYのX値
- 各グループの最小Y値のX値を取得します。
- xatmaxy:X 最大のYのX値
- 各グループの最大Y値のX値を取得します。
サブグループ化の方法でX増分によるまたはグループの数によるを選択した場合、以下の方法を利用可能です。
- begin:サブグループ開始
- 各サブグループの開始の値です。
- center:サブグループ中央
- 各サブグループの中央の値です。
- end:サブグループ終了
- 各サブグループの終了の値です。
|
| Y統合 |
ystats |
入力
int |
0 |
データポイントのグループが統合される出力データポイントのY値を取得する方法を指定します。
オプションリスト:
- ave:平均
- 各グループのデータポイントのY値の平均値を取得します。
- min:最小
- 各グループのデータポイントのY値の最小値を取得します。
- 各グループのデータポイントのY値の最大値を取得します。
- median:中央値
- 各グループのデータポイントのY値の中央値を取得します。
- first:サブグループの最初
- 各グループの最初のデータポイントのY値を取得します。
- last:サブグループの最後
- 各グループの最後のデータポイントのY値を取得します。
- sum:合計
- 各グループのデータポイントのY値の合計を取得します。
- sd:SD
- 各グループのデータポイントのY値の標準偏差を取得します。
- se:SE
- 各グループのデータポイントのY値の標準誤差を取得します。
- rms:RMS
- 各グループのデータポイントのY値の二乗平均平方根を取得します。
|
| 出力 |
oy |
出力
XYRange |
<新規> |
出力範囲を指定します。
このシンタックスを参照してください。
|
| グループ情報を出力 |
rd |
出力
ReportData |
[<same>]<same> |
サブグループ化の方法がref(参照列による)に設定されている場合、このオプションを使って参照列からグループ情報を出力します。
|
説明
このXファンクションは、X値に基づいたXYデータの削減が可能です。X値は単調である必要があります。
データをグループ分けする方法は複数あります。グループ化すると、データポイントの各グループは単一データポイントに統合されます。出力データポイントのXおよびY値の取得方法は指定できます。
サンプル
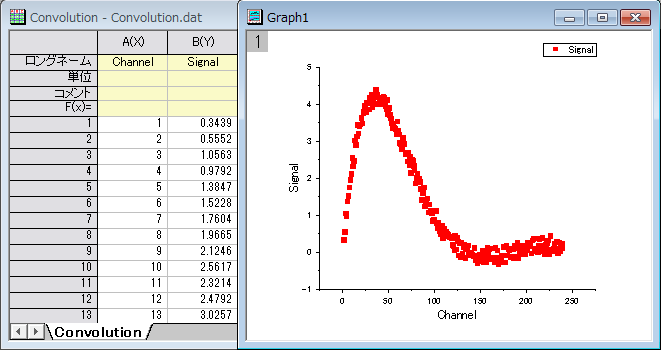
X値が等間隔でないデータセットがあり、X値によってデータを削減したいとします。データセットには200ポイントのデータが含まれています。次の操作を実行すると、これを50ポイントにできます。
- 新しいブックをアクティブにして、単一ASCのインポートボタン
 をクリックして、\Samples\Signal Processing\Convolution.datをインポートします。 をクリックして、\Samples\Signal Processing\Convolution.datをインポートします。
- データ列を選択し、メニューから作図:基本の2Dグラフ:散布図を選択してグラフを作図します。
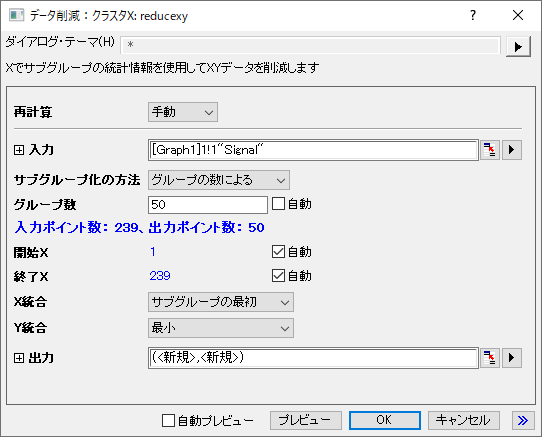
- 解析:データ操作:データ削減:クラスタXを選び、reduceXY Xファンクションダイアログボックスを開きます。
- サブグループ化の方法ドロップダウンリストで、グループの数によるを選択します。グループ数の右側にある自動チェックボックスからチェックを外し、編集ボックスに50を入力します。
- X統合ドロップダウンリストでサブグループの最初を選択します。
- Y統合ドロップダウンリストで最小を選択します。
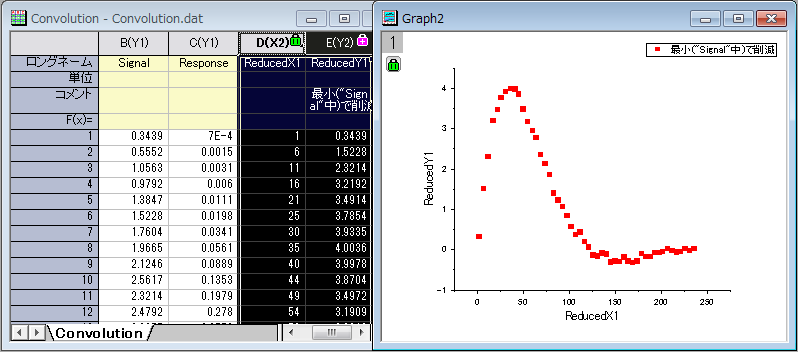
- OKボタンをクリックします。元データの隣の入力ワークシートに結果が出力されます。X2
および Y2を選択し、Originメニューから作図:基本の2Dグラフ:散布図を選択して、グラフを作成します。
以下のスクリプトコマンドを使うことでもデータポイントの削減が可能です。
reducexy -r 2 iy:=[Book2]Convolution!(col(A),col(B)) subgroup:=groups groups:=50 xstats:=first ystats:=min;
関連するXファンクション
stats,
reducedup,
xy_resample
キーワード:データ削減、代表値、平均、合計、最小値、最大値、統計、ビン化
|