fitcmpdata(Pro)
メニュー情報
解析:フィット:データセットの比較
概要
指定のフィッティングモデルを使用して2つのデータセットを比較します
追加の情報
このコマンドはスクリプトからアクセスできません。これはOrigin Proのみの機能です。
Xファンクションの実行オプション
スクリプトからXファンクションにアクセスする場合、追加のオプションスイッチについてのページを参照してください。
変数
表示
名
|
変数
名
|
I/O
と
データ型
|
デフォルト
値
|
説明
|
| フィット結果1
|
result1
|
入力
Range
|
|
異なるデータセットを同じフィットモデルでフィットしたレポートを指定します。
|
| フィット結果2
|
result2
|
入力
Range
|
|
異なるデータセットを同じフィットモデルでフィットしたレポートを指定します。
|
| 有意水準
|
sl
|
入力
double
|
0.05
|
0 から 1 の値を指定可能です。
|
| フィットパラメータ
|
param
|
入力
int
|
1
|
各データセットに対してフィットパラメータを出力するか判断します。
|
| フィット統計
|
statics
|
入力
int
|
1
|
各データセットに対して統計表を出力するか判断します。
|
| 第1データセット名
|
name1
|
入力
string
|
Data1
|
レポートシートの最初のデータセットの表示名を指定します。
|
| 第2データセット名
|
name2
|
入力
string
|
Data2
|
レポートシートの2番目のデータセットの表示名を指定します。
|
| 結果
|
rt
|
出力
ReportTree
|
<new>
|
出力レポートの保存場所を指定します。
|
説明
このツールは2つのデータセットに同じフィットを施すことでこの2つのデータセットを比較します。これは、同じフィットモデルで2つのデータセットがそれぞれ十分異なるかどうかを判定します。よって2つのデータセットは同じ母集団から取得した物かどうかを見極めるツールになります。
このツールを使用するには、次の事に気をつけてください。
- このツールの入力はフィットレポートシート(線形フィット、多項式、非線形曲線フィットなど)です。つまりフィットツールはこのツールを実行する前に行う必要があります。
- フィットツールを使う時には、再計算モードを自動か手動にセットしてください。
- レポートシートの最初の結果のみを使用します。つまり、複数のデータセットをフィットする場合、それぞれ異なるシートに結果が入力されている事が必要です。
サンプル
このサンプルでは、LabTalkスクリプトを使用して以下のデータ比較を行います。
fname$=system.path.program$ + "Samples\Curve Fitting\Exponential Decay.dat"; // データ準備
newbook;
impasc;
nlbegin 1!2 ExpDec1 tt; // 列2で非線形フィット
nlfit;
nlend 1 2; ;
nlbegin 1!3 ExpDec1 tt; // 列3で非線形フィット
nlfit;
nlend 1 2;
fitcmpdata -r 2 result1:=2! result2:=4!; // 指数関数のフィット結果に基づいて2つのデータセットを比較
では、2つのデータセットがあり、それはフィットモデルについて異なるかどうか確認したいと思います。
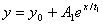
操作
1. \Samples\Curve Fitting フォルダ内にある、 Exponential Decay.dat をインポートします。
2. 列Bを選択し、解析:フィット:非線形曲線フィットを選択してダイアログを開きます。関数をExpDec1にセットします。OK をクリックすると結果シートができます。
3. 列Cを選択して解析:フィット:非線形曲線フィット:1<前回どおり>と操作し、同じモデルで列Cをフィットします。
4. メニューから、解析:フィット:データセット比較を選択してダイアログを開きます。
5. 参照ボタンをクリックしてレポートツリーブラウザを開き、フィット結果1のために項目を一つ選びます。
6. 同じ操作をしてフィット結果2にもう一つの項目を入力します。
7. フィットパラメータとフィット統計を選択してOKをクリックします。
8. F検定の表では、おおざっぱに列Bと列Cは同じモデルに対して異なると結論付ける事ができます。
アルゴリズム
F統計量:
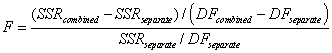
- ここで
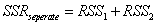 となります となります 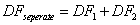
- RSS1は1つ目のデータセットに対する残差の二乗和で、同じようにRSS2は2つ目のデータセット対する残差の二乗和です。SSRcombined は1つ目と2つ目のデータセットの両方を組み合わせたデータセットの残差の二乗和ですい。
確率
- 1-
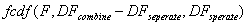
関連 X ファンクション
fitcmpmodel
|