分析テーマによるバッチピーク解析
ピークアナライザのテーマを使用して複数のスペクトルのバッチ処理を実行します
1. paMultiY iy:=[MultiplePeaks]Sheet1!(A,B:E) theme:="IntegratePeaks";
2. paMultiY iy:=[MultiplePeaks]Sheet1!(A,B:E) theme:="IntegratePeaks" number:=2 clear:=1;
3. paMultiY iy:=[MultiplePeaks]Sheet1!(A,B:E) theme:="myPeaksfit" initvalues:=1;
スクリプトからXファンクションにアクセスする場合、追加のオプションスイッチについてのページを参照してください。
| 表示 名 |
変数 名 |
I/O と データ型 |
デフォルト 値 |
説明 |
|---|---|---|---|---|
| 入力 | iy |
入力 XYRange |
|
入力データセットを指定します。Origin 2020b以降、[Book]Sheet!(X,Y1:YN) 形式(X = 共通のX列、Y1:YN = X列の右側のY列の連続した範囲)の短縮構文を使用できます。[Book]Sheet!((X,Y1:YN),(X,YM:YO)) の形式の非連続データからのより複雑な文字列も使用できます。 |
| 分析テーマ | theme |
入力 string |
|
ピーク分析の実行に使用するテーマを指定します。 |
| 結果シート | append |
入力 int |
|
各データセットのピーク分析はワークブックを生成します。この変数でワークブック内のワークシートを選択し、ワークシート内の情報が出力シートに追加されます。
オプションリスト:
|
| レポートにフィット統計を含める | fitresult |
入力 int |
|
レポートシートにフィット統計を含めるか指定します。追加モードが列の場合、GUIでは表示されません。 |
| 出力シート | ow |
出力 Worksheet |
|
各入力データセットに実行されるピーク分析の結果を出力するワークシートを指定します。 |
| 中間結果を削除 | remove |
入力 int |
|
入力データセットにピーク分析を実行することで生成される中間的に出力される分析結果を削除するかどうか指定します。 |
| データセット識別子 | dataid |
入力 string |
|
全範囲、ロングネーム、単位または入力データのユーザ定義パラメータを、レポート内でのデータセット名として指定します。 |
| 指定 | desig |
入力 string |
|
データ識別子のソースを指定し、範囲のX列またはY列からそれを入力します。 |
| 追加の開始行番号 | number |
入力 int |
|
結果が追加される出力ワークシートの開始行を指定します。 |
| 開始時に出力シートをクリア | clear |
入力 int |
|
出力シートに結果を追加する前に出力シートの内容を消去するか指定します。 |
| ラベル行の追加(最初のファイル) | label |
入力 int |
|
最初の結果シートのラベル行を出力シートに追加するか指定します。 |
| 追加モード | mode |
入力 int |
|
データを出力シートに追加する方法を指定します。
オプションリスト:
|
| 連続した初期パラメータ値 | initvalues |
入力 int |
|
このオプションが選択された場合、テーマに保存されたピークの情報はバッチ処理の最初のデータのみに適用されます。連続したデータセットには、前のデータセットのフィット結果から得たピーク初期値が使われます。 |
| 各処理前のスクリプト | beforescript |
入力 string |
|
各入力データセットのピーク分析が実行される前に、この編集ボックスのスクリプトが実行されます。
Note: _rx は i 番目のx データセットの範囲を示します _ry は i 番目のy データセットの範囲を示します _skip は i 番目のファイル/データセットをスキップするか指定します |
| 各処理後のスクリプト | loopscript |
入力 string |
|
各入力データセットのピーク分析の実行時に、この編集ボックスのスクリプトが実行されます。
ここで、_i は i 番目のファイル/データセットのインデックスを示します |
| 終了時のスクリプト | endscript |
入力 string |
|
全入力データセットのピーク分析が実行された後、この編集ボックスのスクリプトが実行されます。 |
| バックグラウンドインスタンスを使用して処理 | instance |
入力 int |
|
複数のOriginプロセスを実行して、処理速度を上げます。最大のメリットを得るには、値をコンピューターの論理コアの数から1を引いた数に設定することをお勧めします。つまり、論理コアの数が8の場合、値を7に設定します。
|
このXファンクションは複数データセットに同じ設定でピークフィットを実行します。設定は、分析テーマファイルに保存されます。異なるデータセットに対して実行される結果はサマリーワークシート内にまとめられます。
次のサンプルは、最初に分析テーマを作成し、次にこのXファンクションの使用して、複数データセットに対してピーク分析を実行する方法を示します。
この例では、ピークアナライザでテーマを作成し、使用する方法を示します。
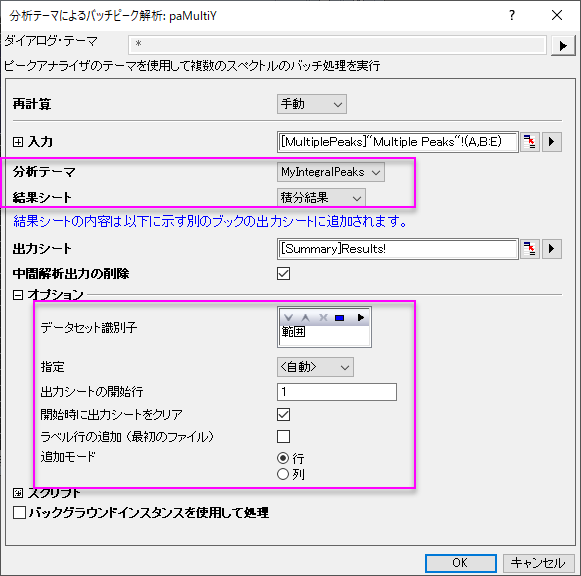
Multiple Peaksワークシートの全てのY列を選択します。メニューから、解析: ピークと基線: 分析テーマによるバッチピーク解析を選択してダイアログを開きます。下図のようにダイアログを設定します。OK ボタンをクリックして、分析を実行します。
X-Function:BatchProcess, blauto, fitpeaks, pa, pkFind, NLfitpeaks
キーワード:スペクトル、サマリーレポート