- 確率プロット:メインメニューで、作図をクリックして、統計を選択して、確率プロット:P-P図をクリックします。 あるいは、 2Dグラフツールバーからの確率プロットボタン(P-P図)
 をクリックします。
をクリックします。 - Q-Qプロット:メインメニューで、作図をクリックして、統計を選択して、Q-Q図をクリックします。 あるいは、 2DグラフツールバーからのQ-Q図ボタン
 をクリックします。
をクリックします。
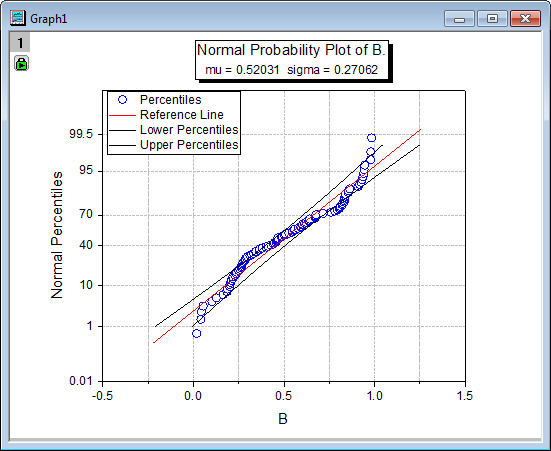
データセットが与えられた分布に従うかどうか検定するために確率プロットを使用します。これは、X軸上に観測した累積パーセント、Y軸上に期待累積パーセントを持つグラフを表示します。すべてのデータポイントが参照線に近い場合、データセットは与えられた分布に従うものと結論付けできます。
Q-Q(Quantile-Quantile) プロットは、データセットが与えられた分布に従うかどうかを検定する手法です。これは、確率プロットとは異なり、XとY軸上でパーセントの変わりに実測値と期待値を示します。すべてのデータポイントが参照線に近い場合、データセットは与えられた分布に従うものと結論付けできます。
Originでは、4つの分布(正規, 正規対数, 指数, ワイブル)と5つのパーセンタイル近似のプロット手法(Blom, Benard, Hazen, Van der Waerden, Kaplan-Meier)をサポートしています。
確率プロット、または、Q-Qプロットを作成するには、
|
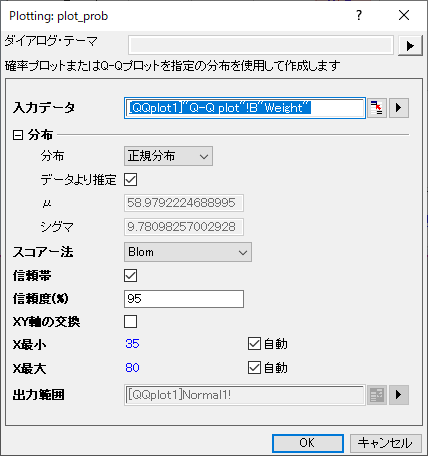
入力データ |
入力データを指定します。 |
|
分布 |
データに対する分布の種類を選択します。分布についてのより詳細な情報は、分布セクションを参照してください。
|
|
スコア法 |
パーセンタイル近似をプロットする方法を選択します。手法についてのより詳細な情報は、スコア法セクションを参照してください。
|
|
信頼帯 |
確率プロットの信頼帯を出力するかどうか指定します。計算の詳細は、アルゴリズムを確認してください。 |
|
信頼度 (%) |
信頼帯が選択されている場合のみ利用できます。選択した分布に対するパーセントで、信頼水準を指定します。 |
| XY軸の交換 |
X軸とY軸を変更するかどうか指定します。 |
| X最小 X最大 |
自動の値は、X最小 = 1 および X最大 = 99.5です。自動のチェックを外すと、出力の参照線列の最小および最大値を使用します。 X最大が自動の値より大きい場合、X最大のパーセント値p1を計算して、 パーセンタイル列には、デフォルトリストにp1およびp1より大きい値のみ含める必要があります。X最大が自動の値より小さい場合、X最大のパーセント値p2を計算して、 パーセンタイル列には、デフォルトリストにp2およびp2より小さい値のみ含める必要があります。 X最小が自動の値よりも小さい場合、X最小値のパーセンタイル値p1を計算します。p1<1e-5, p1=1e-5の場合、p1よりも大きい最小値10^(-m)を見つけ、パーセンタイル列には p1, 10^(-m), 10^(-m+1), ,,,,1, 2,...が含まれます。 X最大が自動の値よりも大きい場合、X最大値のパーセンタイル値p2を計算します。p2>99.99, p2=99.99の場合、リスト (99.9, 99.99) から2より小さい最大値をみつけ、パーセンタイル列には99, 99.5, 99.9,..p2.が含まれます。 |
|
出力範囲 |
グラフのために計算されたデータを保存する場所を設定します。 |
Originには、確率プロットとQ-Qプロットに対して、4つの分布があります。 以下の表に、密度関数を示します。
| 分布 | 密度関数p(x) | 範囲 | パラメータ |
|---|---|---|---|
|
正規分布 |
|
すべて
|
|
|
正規対数 |
|

|
|
|
指数分布 |
|
|
") は、スケールパラメータです。 は、スケールパラメータです。
|
|
Weibull |
|
|
|
|
ガンマ |
|
|
|
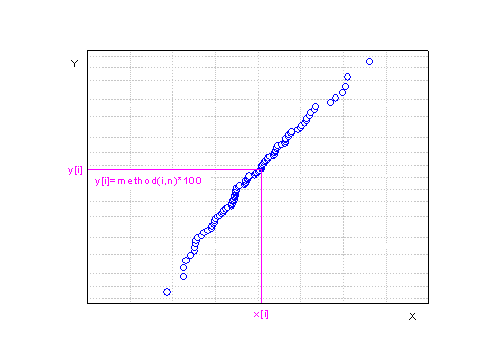
確率プロットを作成して、小さいデータセットから大きいものの順にソートするには、
![x[1]\le x[2]\le x[3]\le \cdots \le x[n-1]\le x[n]](../images/Probability_Plot_and_Q-Q_Plot/math-5624a30d4c678dc72eae5846b1e79702.png "x[1]\le x[2]\le x[3]\le \cdots \le x[n-1]\le x[n]") ,
,  は観測データセットの合計数です。
は観測データセットの合計数です。ソートした観測値は、X座標が![x[i]\](../images/Probability_Plot_and_Q-Q_Plot/math-92f8cb93ad9350ca1ab67868f3667559.png "x[i]\") 、Y座標が スコア法で計算されたポイントで代表されています。
、Y座標が スコア法で計算されたポイントで代表されています。
確率プロットのスケールタイプは、分布により異なります。
| 分布 | Xスケールタイプ | Yスケールタイプ |
|---|---|---|
|
正規分布 |
線形 |
確率 |
|
正規対数 |
Ln |
確率 |
|
指数分布 |
Ln |
2重対数逆数 |
|
Weibull |
Log10 |
2重対数逆数 |
|
ガンマ |
Log10 |
確率 |
Q-Qプロットを作成して、小さいデータセットから大きいものの順にソートするには、
, ここで、は、 観測データセットの合計数です。Y値は、スコア法の逆累積分布関数です。
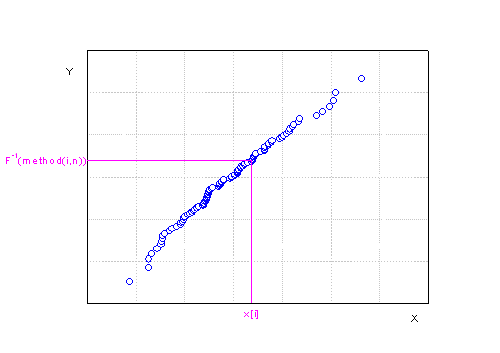
以下に示した方法のひとつを使って、入力値を小さい値から大きい値の順に並べ、ソートデータのシリアル番号がスコア付けされます。 この表では、 がシリアル番号で、は、非欠損入力データです。
がシリアル番号で、は、非欠損入力データです。
| 手法 | プロット位置")
|
|---|---|
|
Blom |
|
|
Benard |
|
|
Hazen |
|
|
Van der Waerden |
|
|
Kaplan-Meier |
|
 ^2}{2\sigma ^2}\right)")
 平均は、位置パラメータ
平均は、位置パラメータ -\mu \right) ^2}{2\sigma ^2}\right)")
")
 ^{c-1}\exp \left( -\left( \frac x\sigma \right) ^c\right)")
") は形状パラメータです。
は形状パラメータです。
\sigma^c}x^{c -1} exp(-x/\sigma),")
/(n+0.25)")
/(n+0.4)")
/n")
")
