このページでは、Origin/OriginProのバージョン2021で追加された、OriginプロジェクトファイルをベースにしたPythonのサンプルを紹介しています。Pythonコードファイルはプロジェクトに添付されています。プロジェクトには、コードを実行するボタンと、コードビルダでコードを表示し、実行したりデバッグするボタンがあります。
これらのプロジェクトは\Samples\Pythonサブフォルダと、F11キーを押して開くラーニングセンターの解析サンプルにあります。
以下は各サンプルの簡単な説明とサンプルに関連するコードです。これにより、Originの組み込みPythonでoriginproパッケージを使って作業する簡単な方法について学ぶことができます。
このサンプルでは、データフォルダのデータを一度にインポートしてバッチピーク分析を実行します。データでは、ベースラインの減算とピークフィットが実行されます。データとフィット結果を表示するグラフにピークパラメータが配置されます。そして、グラフをpngの画像ファイルとしてエクスポートします。
import originpro as op import os path = op.path('e') + "samples\\Batch2\\" for file in os.listdir(path): fullpath = os.path.join(path, file) wks = op.find_sheet(ref='Book1') wks.from_file(fullpath) op.wait() # 処理完了まで待機 op.wait('s', 0.05)#グラフ更新まで待機 weight = wks.get_label(1,'C') # 列コメントを取得してエクスポートグラフの名前にする gp = op.find_graph("Graph1") graphpath = gp.save_fig(op.path()+f'weight - {weight}.png', width=800) print(graphpath) os.startfile(op.path()) # エクスポートグラフのあるフォルダを開く
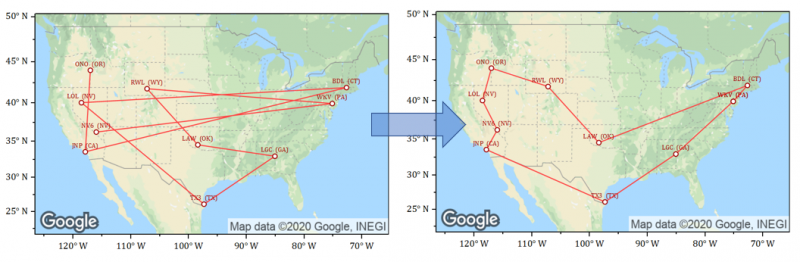
scikit-optパッケージを使って、巡回セールスマン問題について最適な解決策を見つけるサンプルです。あらかじめscikit-optモジュールのインストールが必要です。緯度経度の値をもつ米国の空港データを目的地として使用します。 ランダムに選択された空港の場所と最適化された経路が、Googleマップ画像上のグラフに表示されます。
都市のランダムなセット(ワークシートの行)を選択するコード:
import pandas as pd import originpro as op #「AllAirports」シートからDataFrameにデータを転送 #次に、ランダムに10都市を選び「Selected」シートに置く wksSource = op.find_sheet('w', '[Book2]"All Airports"') df = wksSource.to_df() #スペースがない場合は引用符による囲みは不要 wks = op.find_sheet(ref='[Book2]Selected') wks.clear() wks.from_df(df.sample(10))
距離を最適化するコード:
# scikit_optを使って巡回セールスマン問題を解くPythonコード # 最適化コードは次のページより引用: https://pypi.org/project/scikit-opt/ import sys import numpy as np import pandas as pd import originpro as op # 「Selected」シートに移動してデータを取得 wks = op.find_sheet(ref='[Book2]Selected') lat = wks.to_list('LATITUDE') lon = wks.to_list('LONGITUDE') coordinates = list(zip(lat, lon)) # 列の長さから空港/ポイントの数を取得 num_points = len(coordinates) from scipy import spatial distance_matrix = spatial.distance.cdist(coordinates, coordinates, metric='euclidean') def cal_total_distance(routine): '''The objective function. input routine, return total distance. cal_total_distance(np.arange(num_points)) ''' num_points, = routine.shape return sum([distance_matrix[routine[i % num_points], routine[(i + 1) % num_points]] for i in range(num_points)]) # 最適化 from sko.GA import GA_TSP ga_tsp = GA_TSP(func=cal_total_distance, n_dim=num_points, size_pop=50, max_iter=500, prob_mut=1) best_points, best_distance = ga_tsp.run() # best_pointsをリストに変換 order=best_points.tolist() # ループして行の順序リストを作成 row_order = [0] * num_points count=0 while (count<num_points): row_order[order[count]]=count+1 count=count+1 # 行の順序をワークシートの最初の列に入れ、最初の列でワークシートをソート wks.from_list(0, row_order) wks.sort(0) # 最初の行をコピーして最後に追加し、グラフのループを閉じる row1 = wks.to_list2(0,0) wks.from_list2(row1,num_points)
ワークシートデータにロジスティック回帰を実行するサンプルです。分析で得られたパラメータ値と95%信頼区間は、新しいワークシートに出力されます。最適化処理の情報はスクリプトウィンドウに表示されます。この例では、ワークシートのデータのロジスティック回帰分析を実行します。
#このサンプルはstatsmodelsモジュールのインストールが必要 import pandas as pd import statsmodels.api as sm import originpro as op #アクティブワークシートデータをPythonのDataFrameに送る #ワークシートの列CとDはカテゴリ列 wks = op.find_sheet( 'w' ) df = wks.to_df() #Pythonでロジスティック回帰を実行 cat_columns = df.select_dtypes(['category']).columns df[cat_columns] = df[cat_columns].apply(lambda x: x.cat.codes) df['intercept'] = 1.0 logit = sm.Logit(df['Career_Change'], df[['Age','Salary','Gender','intercept']]) result = logit.fit() #2つのDataFrameをインデックスでマージ:result.params(最初にSeriesをDataFrameに変換)とresult.conf_int() res_df = pd.merge( result.params.to_frame(), result.conf_int(), right_index=True, left_index=True ) res_df.columns = ['Fitted Parameter', '95% CI Lower', '95% CI Upper'] #結果をOriginの新しいワークシートに送る wksR = op.new_sheet( 'w', 'Logistic Regression Result' ) #DataFrame (res_df)をワークシート (wksR)に送る #res_df には3つの列があり、そのインデックスは行名で、これもワークシートに設定する必要がある #DataFrame値をワークシートに送り、DataFrameインデックスの最初の列に送る wksR.from_df( res_df, 0, True )
sklearnパッケージからBayesianRidgeモデルを呼び出すことにより、ベイジアンリッジ回帰を実行するサンプルです。
# このサンプルはsklearnパッケージのインストールが必要 import numpy as np import pandas as pd import originpro as op from sklearn import linear_model # ワークシートExpGrowthを検索 # 1番目と2番目の列をそれぞれX、Yに取得 ws = op.find_sheet('w', 'ExpGrowth') X = np.array(ws.to_list(0)) # 最初の列データをnumpy配列として取得 y = np.array(ws.to_list(1)).ravel() # 2番目の列をnumpy配列として取得 # パラメータを使用してBayesianRidgeオブジェクトを作成 # tol=1e-6, 許容誤差は1e-6 # fit_intercept=True, 切片に合わせる # compute_score=True, 最適化の各反復で対数周辺尤度を計算 # alpha_init=1, ガンマ分布のアルファの初期値 # lambda_init=1e-3, ガンマ分布のラムダの初期値 blr = linear_model.BayesianRidge(tol=1e-6, fit_intercept=True, compute_score=True, alpha_init=1, lambda_init=1e-3) degree = 10 # ヴァンデルモンドの行列取得のため # Xを次数10のファンデルモンド行列に展開 # そしてBayesianRidgeモデルのフィット blr.fit(np.vander(X, degree), y) # Xの同じファンデルモンド行列からyを予測し、標準偏差も返す ymean, ystd = blr.predict(np.vander(X, degree), return_std=True) # 出力結果のワークシートを探す wks = op.find_sheet('w', 'Results') # Xは次数10のファンデルモンド行列に展開されるため、係数を出力 # 10個の係数がある wks.from_df(pd.DataFrame(blr.coef_, columns=['Coefficients']), 0) # 切片を出力 wks.from_df(pd.DataFrame(np.array([blr.intercept_]), columns=['Intercept']), 1) # ガンマ分布のアルファとラムダを出力 wks.from_df(pd.DataFrame(np.c_[['Alpha', 'Lambda'], [blr.alpha_, blr.lambda_]], columns=['Gamma Parameters', 'Gamma Parameter Values']), 2) # 各相互作用のスコア出力 wks.from_df(pd.DataFrame(np.c_[np.arange(0, blr.n_iter_+1), blr.scores_], columns=['Iteration', 'Score']), 4) # 非依存および予測依存、および標準偏差を出力 wks.from_df(pd.DataFrame(np.c_[X, ymean, ystd], columns=['Indep', 'Predicted Y', 'STD']), 6)
FriedmanのSuper Smoother方によりノイズのあるデータにスムージングを実行するサンプルです。
#このサンプルでは、supersmoother およびpandas パッケージのインストールが必要 from supersmoother import SuperSmoother import originpro as op import numpy as np import pandas as pd #アクティブワークシートからデータを取得 wks = op.find_sheet('w') cx = np.array( wks.to_list( 0 ) ) cy = np.array( wks.to_list( 1 ) ) #FriedmanのSuper Smootherを実行 #alpha: smoothing level, (0 < alpha < 10) smoother = SuperSmoother( alpha = 2 ) #smootherをフィット smoother.fit( cx, cy ); #inputxの平滑化関数を予測 yfit = smoother.predict( cx ) #スムージング結果をOriginのワークシートに出力 df = pd.DataFrame( {'Smoothed': yfit} ) wks.from_df( df, 2 )
このサンプルでは、主成分分析(PCA)を使用してイメージスタックデータを削減する方法を示しています。
データは、MATLAB .matファイルの波長範囲にわたるハイパースペクトル画像データです。PCAを使用してデータサイズを削減しますが、それでも多くの有用な情報を保持できます。
import numpy as np import pandas as pd import originpro as op from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA if __name__ == '__main__': # 行列シートMBook1を探す。このシートには、200バンドのハイパースペクトルデータ用に200の行列オブジェクトが画像スタックとして含まれる msX = op.find_sheet('m', 'MBook1') # 行列シートから200バンドのデータを3Dnumpy配列として取得 # dstack=True はdstackを使用し、データは(行、列、深度)の形 # ここでの深度は200、つまり、200バンド # 行と列は、各バンド画像の行と列の数 X = msX.to_np3d(dstack=True) # Xを2D行列に形状変換。ここでは(-1, X.shape[2]) # Xを2D行列に形状変換。ここでは(-1, X.shape[2]) # これは X = np.reshape(X, (X.shape[0]*X.shape[1], X.shape[2]))に等しい # 2D行列に形状変換した後、行列の1行には200のバンド値がある # つまり、行列の1ピクセルには、200枚のスタック画像の深度に沿って200個の値が含まれる X = X.reshape((-1, X.shape[2])) # 行列シートMBook2を探す # このシートに16クラス(1から16まで)のグラウンドトゥルースデータが含まれる # 0は有効なクラスではない msY = op.find_sheet('m', 'MBook2') # グラウンドトゥルースデータを行列シートからnumpy配列として取得 # 次に、1つの列のみを持つ行列として形状変更 # (-1, 1) は最初の次元のサイズにかかわらず1つの列を使用することを意味する mY = msY.to_np3d().reshape((-1, 1)) X = X[mY.ravel() != 0, :] # クラスが0(0は無効なクラスを意味する)であるピクセル(Xの行)を削除 # 元のバンド数は220 # 修正されたデータのバンド数は200 # 吸水領域をカバーするバンドは [104-108], [150-163], 220 # したがって、利用可能なバンドはこれらの20バンドを除外 bands = np.append(np.append(np.array(range(1, 104)), np.array(range(109, 150))), np.array(range(164, 220))) # StandardScalerオブジェクトを作成し、Xデータをフィットおよび変換 # これは、データのさまざまなスケールの問題を回避するためにデータをスケーリングするため scaledX = StandardScaler().fit_transform(X) # 列ヘッダとしてバンドを割り当てることによって # スケーリングされたXデータを使用してDataFrameを作成 scaledX = pd.DataFrame(scaledX, columns=bands) # 列ヘッダが割り当てられますがここではあまり使用しない n_components = 50 # データには200の特徴(1つのサンプルの波)がある。ここでは50使用して、次元を200から50に減らします。 pca = PCA(n_components=n_components, svd_solver='randomized', whiten=True, random_state=100, copy=True) # PCAオブジェクト作成 # pcaオブジェクトを使ってscaledXデータをフィットおよび変換 # データは同じ行数の50列 pcaX = pca.fit_transform(scaledX) # 50個の成分のそれぞれによって説明される分散のパーセンテージの合計を出力 print(np.sum(pca.explained_variance_ratio_)) ws = op.new_sheet('w') # 出力データ用ワークシートを作成 # PCA結果データpcaXを使用してDataFrameを作成 # 列ヘッダは、各成分の説明された分散比 df = pd.DataFrame(pcaX, columns=pca.explained_variance_ratio_.astype('str')) ws.from_df(df) # DataFrameをワークシートに置く
この例(Sample\PythonのExtract Image Colors.opju)では、出版物のグラフ画像などの画像からすべての色を取得できます。各色のRGB値およびOriginの色値がワークシートに出力されます。
import extcolors import numpy as np import originpro as op file_path = op.file_dialog('*.png;*.jpg;*.bmp','Select an Image') if len(file_path) ==0: raise ValueError('user cancel') colors, pixel_count = extcolors.extract_from_path(file_path) colors = np.array(colors) #rgb = colors[:,0] rgb,pixel = map(list, zip(*colors)) #print(rgb) r = [] g = [] b = [] for row in rgb: r.append(row[0]) g.append(row[1]) b.append(row[2]) #色を出力 wks = op.find_sheet('w') wks.from_list(0, r) wks.from_list(1, g) wks.from_list(2, b)
このサンプルでは、間隔が不均一な信号のLomb-Scargleピリオドグラムを計算します。
#このサンプルはscipy、pandasパッケージのインストールが必要 import originpro as op import numpy as np from scipy.signal import lombscargle import pandas as pd #アクティブワークシートを使用し、列A、Bのデータを取得 wks = op.find_sheet() t = np.array( wks.to_list( 0 ) ) y = np.array( wks.to_list( 1 ) ) #lombscargle 関数の入力として角周波数を計算 n = t.size ofac = 4 # オーバーサンプリング因子 hifac = 1 T = t[-1] - t[0] Ts = T / (n - 1) nout = np.round(0.5 * ofac * hifac * n) f = np.arange(1, nout+1) / (n * Ts * ofac) f_ang = f * 2 * np.pi #Lomb-Scargleピリオドグラム分析を実行 pxx = lombscargle(t, y, f_ang, precenter=True) pxx = pxx * 2 / n /f[-1] #f 単位: mHz, PSD 単位: dB/Hz f = 1000*f pxx = 10*np.log10( pxx ) df = pd.DataFrame( {'Frequency':f, 'Power/Frequency':pxx} ) #PythonのDataFrameをワークシート列3から送る wks.from_df( df, 2 )
このサンプル(\Samples\PythonのExport all Graphs.opju)はOriginプロジェクトの全グラフをエクスポートします。このプロジェクトには、それぞれに1つのグラフを持つ2つのサブフォルダがあります。グラフは以前にエクスポートされているため、各グラフにエクスポート設定が自動的に保存されています。
Run Codeボタンをクリックすると下に表示されているLabTalkスクリプトを実行します。スクリプトによりGetNダイアログボックスが開き、エクスポートパスの指定や他の設定が可能です。
string path$ = ""; int fmt=0; double dWidth = 500; int bWidth = 0; GetN (Leave path empty and Format Auto to use settings in each graph) $:@HL (Export Path) path$:@BBPath (Format) fmt:r("Auto|png") (Change Width) bWidth:2s1 (New Width) dWidth (Graph Export Options); if(0==bWidth) dWidth = 0; py.@expall(path$, dWidth, fmt);
スクリプトの最後の行は、グラフをエクスポートするPython関数を呼び出します。py.@expall()という特別な表記は、expall()関数が、プロジェクトに添付されているexp.pyファイルに含まれていることを表しています。
以下にPython関数のコードを示します。
import os import originpro as op def expall(fpath, imgw, usepng): #埋め込みグラフを含むプロジェクト内のグラフを全て検索 list = op.graph_list('p') for graph in list: if usepng==0 and imgw==0: #グラフに保存されたテーマを使用。fpathが空でない場合パスを変更 #そうでない場合、各グラフに独自のパスを記録 result = graph.save_fig(fpath) else: result = graph.save_fig(path=fpath, type='png', width=imgw) print(result) #LTパスから与えられた場合 if len(fpath): os.startfile(fpath)
opencvパッケージを使用して画像の細線化を実行するサンプルです。
#元のコード: https://theailearner.com/tag/thinning-opencv/ #pip install opencv-python;// スクリプトウィンドウでcv2をインストールする場合 import cv2 import numpy as np import originpro as op #ソース画像をnumpy配列imgにロード m1 = op.find_sheet('m', 'MBook1') img = m1.to_np2d() # 構造化要素 kernel = cv2.getStructuringElement(cv2.MORPH_CROSS,(3,3)) # 値を保持するために空の出力画像を作成 thin = np.zeros(img.shape,dtype='uint8') # 収縮処理が空のセットまたは最大になるまでループ max = 50 while (cv2.countNonZero(img)!=0): # 収縮処理 erode = cv2.erode(img,kernel) # 収縮処理後の画像を開く opening = cv2.morphologyEx(erode,cv2.MORPH_OPEN,kernel) # 2つを減算 subset = erode - opening # 以前のすべてのセットの和集合 thin = cv2.bitwise_or(subset,thin) # 次の反復のために収縮処理した画像を設定 img = erode.copy() max -= 1 if max == 0: break m2 = op.new_sheet('m', 'Thinned Result') m2.from_np(thin) m2.show_image()
このサンプル(Sample\PythonのPeak Movement.opju)では、ワークシートの連続する列からのデータが1つずつプロットされるので、測定パラメータの関数としてデータがどのように変化しているかを視覚化できます。
import originpro as op import pandas as pd #ブック名で検索 wksSource = op.find_sheet('w', 'Waterfall]') df = wksSource.to_df() #範囲表記でも検索可能 wks = op.find_sheet(ref="[Book1]1!") for key, value in df.iteritems(): wks.from_list(key!='X', list(value), comments=key) op.wait('s', 0.05)
複数の総和を持つ関数にデータをフィットさせるサンプルです。ベクトル形式でフィトパラメータを取得するためにNelder-Meadシンプレックスアルゴリズムが使用されます。
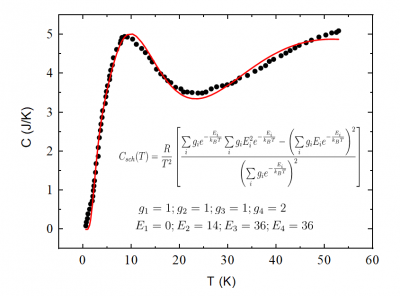
import numpy as np from scipy.optimize import minimize import originpro as op def fitfunc(a): y1 = np.array(y) y1 = y1.reshape(1,len(y1)) return sum(np.square(sum(C_csk(a, x) - y1))) def C_csk(a, x): """ D:DD """ a = np.array(a) a = a.reshape(len(a),1) g = a[0:int(len(a)/2)] d = a[int(len(a)/2):] x1 = np.array(x) x1 = x1.reshape(1,len(x1)) m0 = g*np.exp(-d/x1) m1 = g*d*np.exp(-d/x1) m2 = g*np.square(d)*np.exp(-d/x1) sm = (m0.sum(axis=0)*m2.sum(axis=0) - np.square(m1.sum(axis=0)))/np.square(m0.sum(axis=0))*8.314/x1/x1 return sm.sum(axis=0) def fitSummation(): global x, y wks = op.find_sheet() x = wks.to_list(0) y = wks.to_list(1) a0 = np.array(wks.to_list(2)) res = minimize(fitfunc, a0, method='nelder-mead', options={'xatol': 1e-8, 'disp': True}) wks.from_list(3, res.x)
テキストラベルなどのグラフオブジェクトからLabTalkスクリプトを実行するように設定できます。クリック、移動、サイズ変更などのイベントによりスクリプトを実行可能です。
前のセクションで説明したサンプルでは、ボタンとして設定されたテキストラベルを使用して、LabTalkスクリプトを実行します。次に、スクリプトはプロジェクトに添付されたPythonコードを実行します。次のミニチュートリアルでは、その方法を説明します。
print('Hello from Python!')上書き保存ボタンをクリックしてファイルを保存します。
run -pyp test.py;.このスクリプトは、プロジェクトに添付されたtest.pyファイルのPythonコードを実行するようにOriginに伝えるためのものです。
インストール時に付属するOriginのプロジェクトサンプルには、コードを実行する、コードを表示する、必要なパッケージをインストールするなどの複数のボタンがあります。ALTキーを押しながら、これらのボタンをダブルクリックすると、スクリプトが表示されます。
上記のプロジェクトには、コードを表示するボタンがあり、クリックすると、コードビルダーIDEでPythonコードが開きます。プロジェクトに添付されている.pyファイルが1つしかない場合は、次のスクリプト行でそのファイルをIDEで開くことができます。
ed.open(py.@)
プロジェクトに複数のファイルが添付されている場合は、以下のようにして特定のファイルを開くことができます。
ed.open(py.@filename)
Altキーを押しながらコードを表示するボタンをダブルクリックすると、このスクリプトを実行するためのボタンの設定を確認できます。
関連情報: